8 生物学分析
8.1 聚类介绍
对数据进行了标准化并移除了混淆因子后,就可以进行与手头的生物学问题相关的分析。分析的性质取决于数据集。 然而,一些方面在广泛的背景下有用,我们将在接下来的几章中讨论其中的一些方面。从scRNA-seq数据的聚类开始。
8.1.1 介绍
scRNA-seq最有希望的应用之一是基于转录谱的de novo发现和注释细胞类型。在计算上,这是一个难题,因为它相当于非监督聚类。 也就是说,我们需要根据转录组的相似性识别细胞群,不需要对细胞类型的任何先验知识。 此外,在大多数情况下,我们甚至不知道先验集群的数量。由于噪音(技术和生物)和高维度(比如基因),问题变得更具挑战性。
8.1.2 降维
在处理大型数据集时,应用某种降维方法是有帮助的。将数据投影到较低维度的子空间上,能够显著减少噪声。另一个好处是,在2维或3维子空间中可视化数据要容易得多。我们已经讨论了PCA(章节 7.3.2)和t-SNE(章节 7.3.2)。
8.1.3 聚类方法
非监督聚类 在机器学习中广泛研究并应用于不同领域。常用的流行方法是:层次聚类,k-means聚类,基于的图聚类。
8.1.3.1 层次聚类
层次聚类可以使用自下而上或自上而下的方法。自下而上策略中,每个细胞最初单独为一类,随后将类进行合并形成hieararchy:
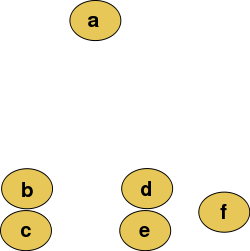
Figure 8.1: 原始数据
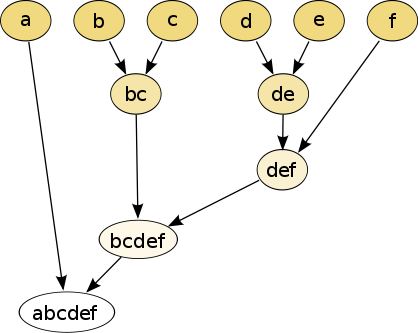
Figure 8.2: 层次聚类树状图
使用自上而下策略,最初所有观测点为一类,递归对类进行拆分拆分形成hierarchy。该策略的一个优点是该方法是确定性的。
8.1.3.2 k-means
k-means聚类,将 _N_个细胞划分成 _k_个不同的类。以迭代的方式,分配类中心并将每个细胞分配个最近的类。
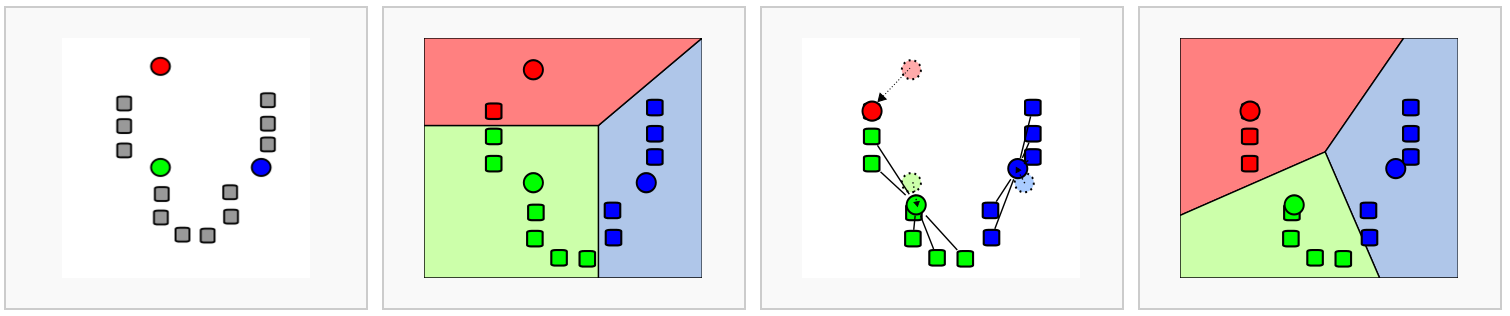
Figure 8.3: Schematic representation of the k-means clustering
scRNA-seq分析的大多数方法在某些步骤都包括 k-means环节。
8.1.3.3 基于图的方法
在过去的二十年中,人们对分析各个领域的网络产生了很大的兴趣。 一个目标是识别网络中节点的群体或模块。
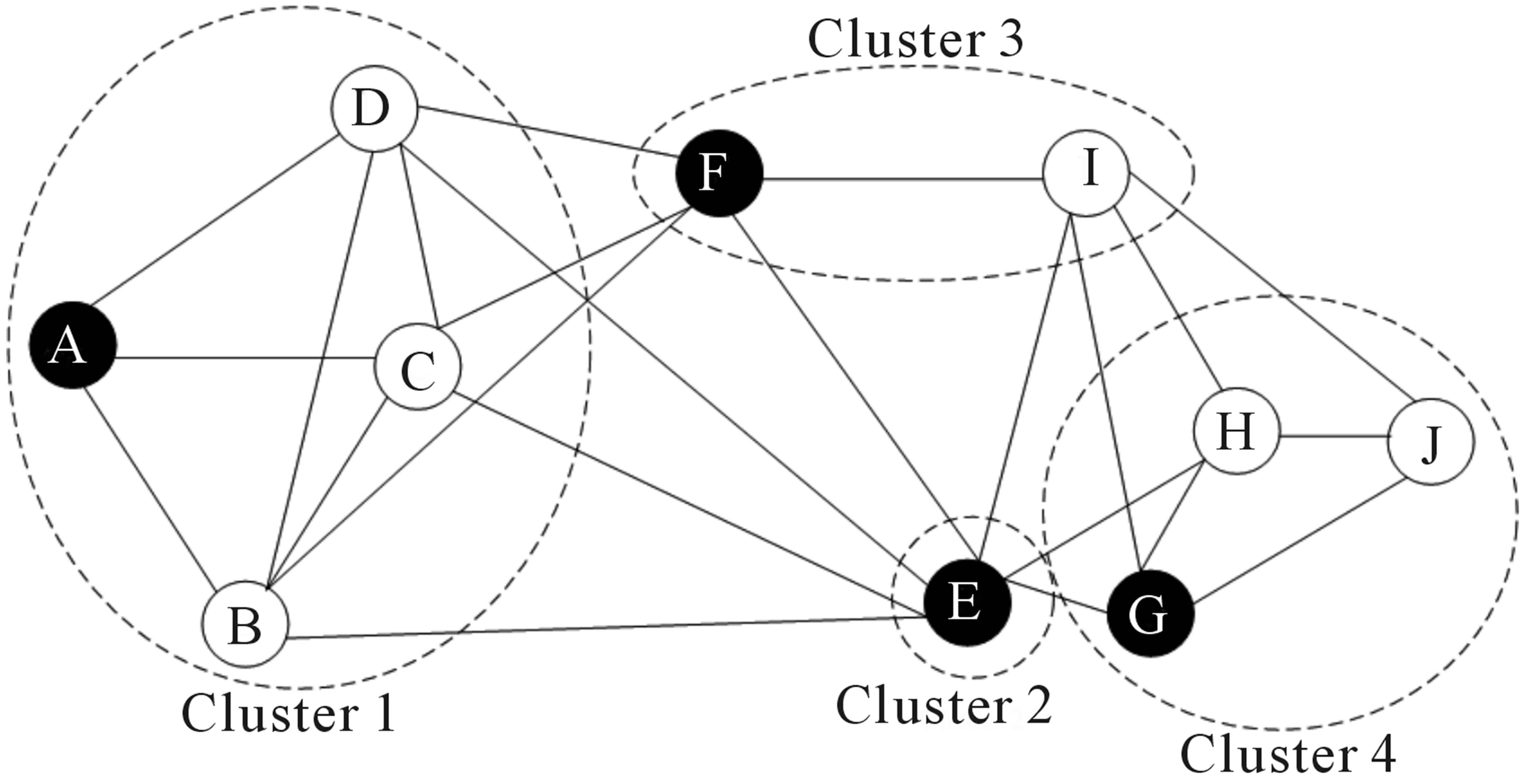
Figure 8.4: Schematic representation of the graph network
通过构建图,其中每个节点代表一个细胞,一些方法可以应用于scRNA-seq数据。 然而,构建图并为边指定权重并非易事。 基于图的方法的一个优点是其中一些方法非常有效,可以应用于包含数百万节点的网络。
8.1.4 聚类的挑战
- 类个数 _k_的确定?
- 什么是细胞类型?
- 可拓展性:在过去的几年中,scRNA-seq实验的细胞数量增长了几个数量级,从~\(10^2\) 到 ~\(10^6\)
- 工具不太友好
8.1.5 scRNA-seq数据的工具
8.1.5.2 SC3
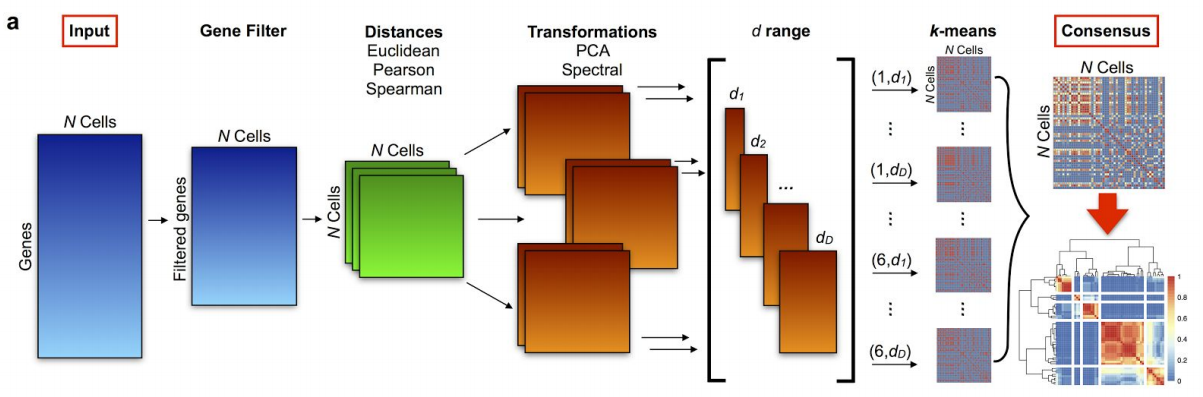
Figure 8.5: SC3 pipeline
- SC3 (Kiselev et al. 2017) 基于PCA和谱降维
- 使用 k-means
- 使用一致性聚类(consensus clustering)
8.1.5.3 tSNE + k-means
- 基于 __tSNE__映射
- 使用 k-means
8.1.6 比较聚类结果
可以使用adjusted Rand index比较聚类效果。 该指数衡量两个数据cluster之间的相似性。ARI指数的值位\([0;1]\)区间,其中\(1\)表示两个聚类相同,\(0\)表示随机相似程度。
8.2 聚类示例
library(pcaMethods)
library(SC3)
library(scater)
library(SingleCellExperiment)
library(pheatmap)
library(mclust)
set.seed(1234567)为说明scRNA-seq数据聚类,使用来自小鼠发育胚胎细胞(Deng et al. 2014)的Deng数据集。 我们已经对数据集进行预处理并创建SingleCellExperiment对象。 而且利用文章中识别的细胞类型对细胞进行注释(colData中cell_type2列)。
8.2.1 Deng 数据集
加载数据:
deng <- readRDS("data/deng/deng-reads.rds")
deng
## class: SingleCellExperiment
## dim: 22431 268
## metadata(0):
## assays(2): counts logcounts
## rownames(22431): Hvcn1 Gbp7 ... Sox5 Alg11
## rowData names(10): feature_symbol is_feature_control ...
## total_counts log10_total_counts
## colnames(268): 16cell 16cell.1 ... zy.2 zy.3
## colData names(30): cell_type2 cell_type1 ... pct_counts_ERCC
## is_cell_control
## reducedDimNames(0):
## spikeNames(1): ERCC查看细胞类型注释:
table(colData(deng)$cell_type2)
##
## 16cell 4cell 8cell early2cell earlyblast late2cell
## 50 14 37 8 43 10
## lateblast mid2cell midblast zy
## 30 12 60 4简单的PCA分析已经分离出一些细胞类型,并初步了解了数据结构:

如上图所示,早期细胞类型分得很靠,但三个囊胚时间点难以区分。
8.2.2 SC3
在Deng数据上运行SC3聚类,SC3的优点是其可以直接使用SingleCellExperiment对象。
假设我们不知道类 k(细胞类型)的数目,SC3可以对cluster数目进行估计。
有趣的是,SC3预测的细胞类型数量小于原始数据注释。 然而,不同细胞类型的早期,中期和晚期,刚好有6种细胞类型。 将合并的细胞类型存储在colData的cell_type1列中:

下面运行SC3(同时计算类的生物学特性):
SC3结果由几部分组成(详见(Kiselev et al. 2017)和SC3 vignette),这里展示一些:
一致性矩阵:
 Silhouette图:
Silhouette图:
 表达矩阵热图:
表达矩阵热图:
 识别的marker基因:
识别的marker基因:

SC3类PCA图:

SC3聚类结果和文献中细胞类型比较:
注意 SC3可以在Shiny会话中以交互形式运行:
上述命令会在浏览器中打开SC3。
注意 当细胞数量\(>5000\),直接计算SC3距离非常慢。对于包含超过\(10^5\)细胞的大型数据集,推荐使用Seurat(见章节 9)。
练习1: 在浏览器中运行
SC3,设置\(k\)从8-12,查看不同的聚类结果;练习2: 哪种聚类结果最稳定(查看“Stability”标签);
练习3: 使用\(k=10\),查看cluster中差异表达基因和marker基因;
练习4: 更改marker基因阈值(默认为0.85)。SC3 找到更多的marker基因了吗?
8.2.3 tSNE + kmeans
之前(7.3.3)用 __scater__包画tSNE图是用Rtsne 和 ggplot2做的。这里也同样:

Figure 8.6: tSNE map of the patient data
注意,上图中的所有点都是黑色的。这与之前看到的不同,当时基于注释对细胞进行着色。 这里没有任何注释,所有细胞都来自同一批次,因此所有点都是黑色的。
现在将 k-means聚类算法应用到tSNE映射上的点云上。你在点云看到了多少组?
从\(k=8\)开始:
colData(deng)$tSNE_kmeans <- as.character(kmeans(deng@reducedDims$TSNE, centers = 8)$clust)
plotTSNE(deng, colour_by = "tSNE_kmeans")
Figure 8.7: tSNE map of the patient data with 8 colored clusters, identified by the k-means clustering algorithm
练习7: 设置\(k=10\).
练习8: 比较tSNE+kmeans结果和文献中细胞类型,当改变perplexity参数时,结果会提高吗?
答案:
colData(deng)$tSNE_kmeans <- as.character(kmeans(deng@reducedDims$TSNE, centers = 10)$clust)
adjustedRandIndex(colData(deng)$cell_type2, colData(deng)$tSNE_kmeans)您可能已经注意到,tSNE+kmeansj结果是随机的,每次运行时都会给出不同的结果。 为了获得更好的结果,我们需要多次运行该方法。 SC3也是随机的,但由于consensus步骤,更稳健,不太可能产生不同的结果。
8.2.4 SINCERA
SINCERA基于层次聚类。注意,SINCERA在聚类之前进行基因尺度z-score转换:
# perform gene-by-gene per-sample z-score transformation
dat <- apply(input, 1, function(y) scRNA.seq.funcs::z.transform.helper(y))
# hierarchical clustering
dd <- as.dist((1 - cor(t(dat), method = "pearson"))/2)
hc <- hclust(dd, method = "average")如果cluster数量未知, SINCERA 将k识别为生成不超过指定数量的单个cluster(仅包含1个细胞的clusters)的层次树的最小高度。
num.singleton <- 0
kk <- 1
for (i in 2:dim(dat)[2]) {
clusters <- cutree(hc, k = i)
clustersizes <- as.data.frame(table(clusters))
singleton.clusters <- which(clustersizes$Freq < 2)
if (length(singleton.clusters) <= num.singleton) {
kk <- i
} else {
break;
}
}
cat(kk)
## 6用热图对SINCERA结果进行可视化:

Figure 8.8: Clustering solutions of SINCERA method using found \(k\)
练习10: 比较SINCERA结果和文献细胞类型。
答案:
colData(deng)$SINCERA <- as.character(cutree(hc, k = kk))
adjustedRandIndex(colData(deng)$cell_type2, colData(deng)$SINCERA)
## [1] 0.3823537练习11: 使用单例cluster标准确定k效果好吗?
8.3 特征选择
library(scRNA.seq.funcs)
library(matrixStats)
library(M3Drop)
library(RColorBrewer)
library(SingleCellExperiment)
set.seed(1)单细胞RNASeq能够检测每个细胞中数千个基因的表达。 然而,在大多数情况下,只有一部分基因对感兴趣的生物学条件的做出响应,例如, 细胞类型的差异,分化的驱动因素,对环境刺激的响应。 由于技术噪音,在scRNA-Seq实验中检测到的大多数基因仅在不同水平检测到。 这导致技术噪声和批量效应会混淆感兴趣的生物信号。
因此,进行特征选择以去除那些仅表现出来技术噪音的基因。这不仅会增加数据中的信噪比; 还通过减少数据量来降低分析的计算复杂性。
对于scRNASeq数据,我们将关注于非监督的特征选择方法,这些方法不需要任何先验信息,例如细胞类型或生物组,因为对大多数实验得不到这些信息,或者不可靠的。与之相反,差异表达(章节 8.6)可以被认为是监督特征选择的一种形式,因为它使用每个样本的已知生物标记来识别在不同组间差异表达的特征(如基因)。
在本节中,我们将继续使用Deng数据。
deng <- readRDS("data/deng/deng-reads.rds")
celltype_labs <- colData(deng)$cell_type2
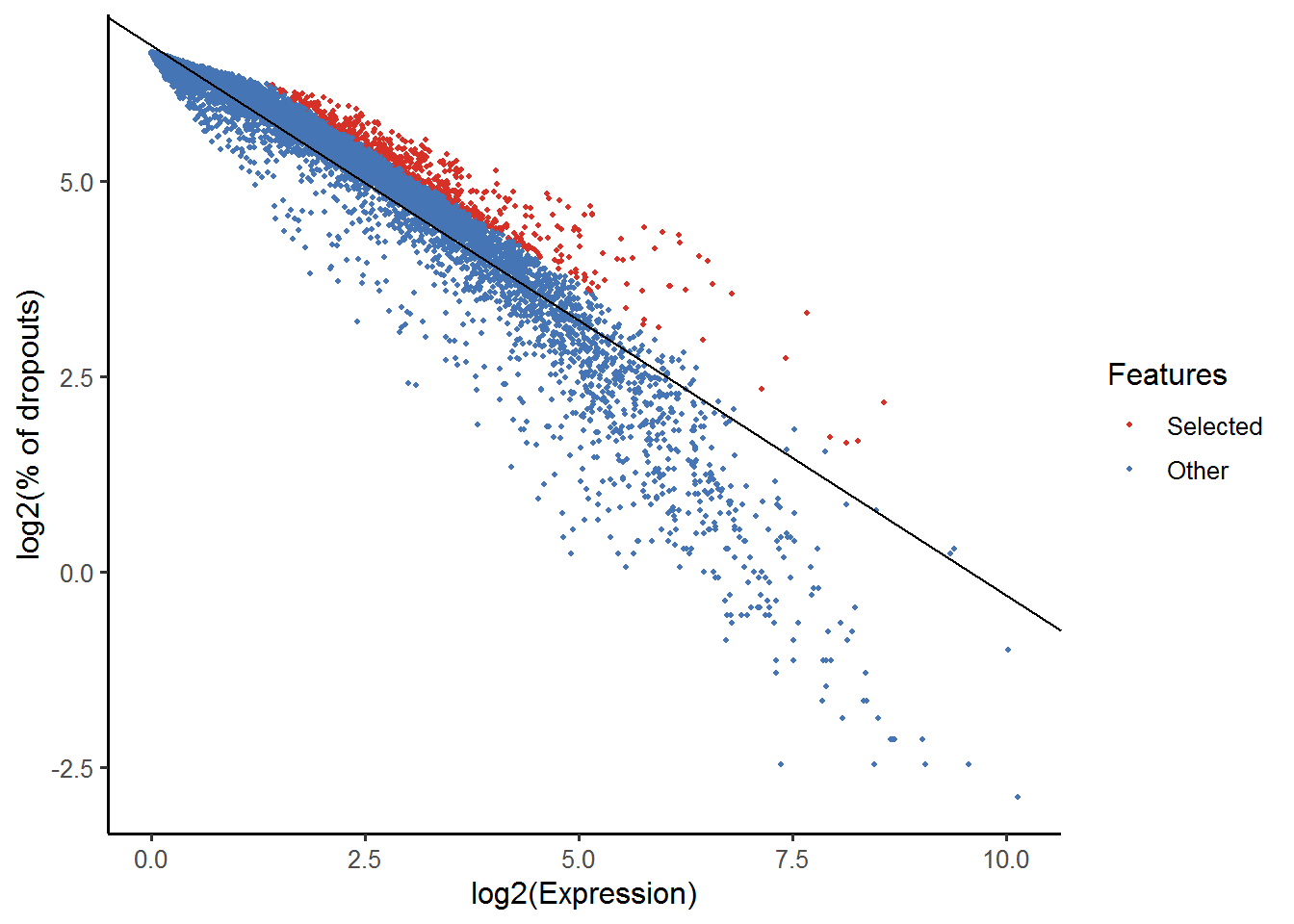
cell_colors <- brewer.pal(max(3,length(unique(celltype_labs))), "Set3")特征选择在质控后执行,但是此数据已经质控过,因此可以跳过该步骤。 M3Drop包含两种不同的特征选择方法,一个是“M3DropFeatureSelection”,基于Michaelis-Menten曲线,为全长转录本scRNA-seq(如Smartseq2)设计;另一个是“NBumiFeatureSelectionCombinedDrop”,基于负二项模型,专为UMI count数据而设计。我们在Deng Smartseq2数据上进行演示。
M3Drop特征选择使用标准化(但不是对数变换)表达矩阵。 使用以下命令从SingleCellExperiment对象中提取。
此功能与大多数scRNA-seq分析包兼容,包括:scater,SingleCellExperiment,monocle和Seurat。 如果指定矩阵是原始count或者对数转换,它可以将其转换为正确的形式(删除未检测到的基因和标准化/delogging)。查看帮助手册以获取详细信息:
练习1: 确认转换函数已经删除未检测到的基因:
nrow(counts(deng)) - nrow(expr_matrix)
summary( rowSums(counts(deng))[! rownames(counts(deng)) %in% rownames(expr_matrix) ] )8.3.1 识别基因与null模型
无监督特征选择主要有两种方法。 第一个是识别与描述数据集中预期的技术噪声的null模型不同的基因。
如果数据集包含spike-in RNAs,其可以用于直接模拟技术噪音。然而,spike-ins可能不像内源转录本经历相同的技术噪音 (Svensson et al., 2017)。而且,scRNA-seq实验只包含一小部分spike-ins,对拟合模型参数可能不足。
8.3.1.1 Highly Variable Genes
提出用于鉴定scRNA-Seq数据集特征的第一种方法是鉴定高度可变的基因(HVG)。 HVG假设如果基因在细胞间的表达差异很大,那么这些差异中的一部分是由于细胞之间的生物学差异而不是技术噪声。然而,由于count data的性质,基因的表达均值与细胞read count的方差之间存在正相关关系。必须纠正这种关系才能正确识别HVG。
练习2 使用rowMeans和rowVars函数绘制此数据集中所有基因的表达的均值和方差之间的关系。 (提示:使用log =“xy”在对数刻度上绘图)。
plot(
rowMeans(expr_matrix),
rowVars(expr_matrix),
log="xy",
pch=16,
xlab="Mean Expression",
ylab="Variance",
main=""
) Brennecke et al.提出了一种纠正方差和平均表达之间关系的方法。为使用Brennecke方法,首先对文库大小进行标准化,然后计算均值和变异系数(方差除以表达均值)。对于ERCC spike-in,用二次曲线拟合这两个变量之间的关系,然后使用卡方检验来找到显著高于曲线的基因。此方法作为Brennecke_getVariableGenes(counts, spikes)函数包含在M3Drop包中。 但是,此数据集不包含spike-ins,因此使用整个数据集来估计技术噪声。
Brennecke et al.提出了一种纠正方差和平均表达之间关系的方法。为使用Brennecke方法,首先对文库大小进行标准化,然后计算均值和变异系数(方差除以表达均值)。对于ERCC spike-in,用二次曲线拟合这两个变量之间的关系,然后使用卡方检验来找到显著高于曲线的基因。此方法作为Brennecke_getVariableGenes(counts, spikes)函数包含在M3Drop包中。 但是,此数据集不包含spike-ins,因此使用整个数据集来估计技术噪声。
在下图中,红色曲线是拟合的技术噪声模型,虚线是95%置信区间。 粉红点是多次测试校正后具有显著生物变异性的基因。

该函数返回显著基因的矩阵以及估计效应大小(观察和预期的变异系数之间的差异),以及原始p值和FDR校正q值的显著性。保留显著HVG基因的名称。
_练习3__ 使用BrenneckeGetVariableGenes有多少基因是显著的?
8.3.1.2 High Dropout Genes
另外一种寻找HVGs是识别具有非常多0值表达的基因。0的频率称之为dropout rate,和scRNA-seq数据中表达水平密切相关。scRNA-seq数据中表达矩阵超过一半的基因表达值为0,因为单细胞中mRNA无法被逆转录(Andrews and Hemberg, 2016)。逆转录是酶促反应,可以使用Michaelis-Menten方程模拟:
\[P_{dropout} = 1 - S/(K + S)\]
其中\(S\)为细胞中mRNA浓度(使用平均表达值来估计),\(K\)是Michaelis-Menten常数。
由于Michaelis-Menten方差是非线性凸函数,数据集中细胞间差异表达的基因位于Michaelis-Menten模型的上/右方(见下图)。
K <- 49
S_sim <- 10^seq(from = -3, to = 4, by = 0.05) # range of expression values
MM <- 1 - S_sim / (K + S_sim)
plot(
S_sim,
MM,
type = "l",
lwd = 3,
xlab = "Expression",
ylab = "Dropout Rate",
xlim = c(1,1000)
)
S1 <- 10 # Mean expression in population 1
P1 <- 1 - S1 / (K + S1) # Dropouts for cells in condition 1
S2 <- 750 # Mean expression in population 2
P2 <- 1 - S2 / (K + S2) # Dropouts for cells in condition 2
points(
c(S1, S2),
c(P1, P2),
pch = 16,
col = "grey85",
cex = 3
)
mix <- 0.5 # proportion of cells in condition 1
points(
S1 * mix + S2 * (1 - mix),
P1 * mix + P2 * (1 - mix),
pch = 16,
col = "grey35",
cex = 3
) 注意: 将
注意: 将log="x"加入plot函数,查看log尺度下的图像。
练习4: 使用不同表达水平(S1 & S2)或混合进行作图。
plot(
S_sim,
MM,
type = "l",
lwd = 3,
xlab = "Expression",
ylab = "Dropout Rate",
xlim = c(1, 1000),
log = "x"
)
S1 <- 100
P1 <- 1 - S1 / (K + S1) # Expression & dropouts for cells in condition 1
S2 <- 1000
P2 <- 1 - S2 / (K + S2) # Expression & dropouts for cells in condition 2
points(
c(S1, S2),
c(P1, P2),
pch = 16,
col = "grey85",
cex = 3
)
mix <- 0.75 # proportion of cells in condition 1
points(
S1 * mix + S2 * (1 - mix),
P1 * mix + P2 * (1 - mix),
pch = 16,
col = "grey35",
cex = 3
)使用M3Drop识别MM曲线右侧的显著异常值。应用1%FDR多重假设校正:
M3Drop_genes <- M3DropFeatureSelection(
expr_matrix,
mt_method = "fdr",
mt_threshold = 0.01
)
M3Drop_genes <- M3Drop_genes$Gene
M3Drop包中包含另一种方法,法专门针对UMI-tagged数据,该数据通常包含由低序列覆盖率以及逆转录不足,产生的许多0值。该模型是Depth-Adjusted Negative Binomial (DANB)。 该方法将每个表达观测描述为负二项模型,其均值和相应基因的平均表达和相应细胞的测序深度相关,其方差和基因的平均表达相关。
此方法直接对数据集中的raw counts进行建模,可以使用类似于M3Drop的“NBumiConvertData”函数提取相应的矩阵。 然而,我们有一个额外的步骤来拟合模型,因为这是该方法的最慢步骤,我们目前正在研究其他方法,可以将此模型信息用于其他方面(如标准化,共表达测试,检测HVG)。
该方法包括对每个特征的重要性进行二项式检验,但由于Deng数据不是UMI counts,因此模型不能充分地拟合噪声,并且太多基因检测为显著的。 因此,我们将按x效应大小去Top1500。
deng_int <- NBumiConvertData(deng)
DANB_fit <- NBumiFitModel(deng_int) # DANB is fit to the raw count matrix
# Perform DANB feature selection
DropFS <- NBumiFeatureSelectionCombinedDrop(DANB_fit, method="fdr", qval.thresh=0.01, suppress.plot=FALSE)
DANB_genes <- DropFS[1:1500,]$Gene 练习5
使用NBumiFeatureSelectionCombinedDrop有多少基因是显著的?
练习5
使用NBumiFeatureSelectionCombinedDrop有多少基因是显著的?
8.3.2 Correlated Expression
和之前方法不同时使用基因-基因相关性。该方法基于多个基因将在不同细胞类型或细胞状态之间差异表达。在相同细胞群中表达的基因彼此正相关,其中在不同细胞群中表达的基因将彼此负相关。因此,通过基因间相关程度来鉴定重要基因。
这种方法的局限性在于它假设技术噪声对于每个细胞是随机且独立的,因此不产生基因-基因相关性,但是这种假设被批次效应所违背,批次效应通常在不同的实验批次之间并且产生基因-基因相关性。因此,通过基因-基因相关性排序选择前几千个基因比考虑相关性的显著性更合适。
最后,scRNA-Seq数据分析中另一种常用的特征选择方法是使用PCA loadings。具有高PCA loadings的基因可能是高度可变的并且与许多其他可变基因相关,因此可能与潜在的生物学性质相关。然而,与基因-基因相关性一样,PCA loading对批次效应敏感; 因此,建议绘制PCA结果以确定对应生物变异而不是批次效应的组成分。
# PCA is typically performed on log-transformed expression data
pca <- prcomp(log(expr_matrix + 1) / log(2))
# plot projection
plot(
pca$rotation[,1],
pca$rotation[,2],
pch = 16,
col = cell_colors[as.factor(celltype_labs)]
) 
# calculate loadings for components 1 and 2
score <- rowSums(abs(pca$x[,c(1,2)]))
names(score) <- rownames(expr_matrix)
score <- score[order(-score)]
PCA_genes <- names(score[1:1500])练习6 查看前5个组成分,哪个与生物学现象最相关?如果考虑这些组成分的loadings,Top1500个特征如何变化?
plot(
pca$rotation[,2],
pca$rotation[,3],
pch = 16,
col = cell_colors[as.factor(celltype_labs)]
)
plot(
pca$rotation[,3],
pca$rotation[,4],
pch = 16,
col = cell_colors[as.factor(celltype_labs)]
)
# calculate loadings for components 1 and 2
score <- rowSums(abs(pca$x[,c(2, 3, 4)]))
names(score) <- rownames(expr_matrix)
score <- score[order(-score)]
PCA_genes2 = names(score[1:1500])8.3.3 比较不同的方法
检查所识别的特征是否代表了该数据集中细胞类型之间差异表达的基因。
 使用Jaccard指数比较特征选择方法的一致性:
使用Jaccard指数比较特征选择方法的一致性:
练习7
绘制每种方法的基因的表达值,其中哪个是差异表达?该数据集中不同方法的一致性体现在哪里?
list_of_features <- list(
M3Drop_genes,
HVG_genes,
Cor_genes,
PCA_genes,
PCA_genes2
)
Out <- matrix(
0,
ncol = length(list_of_features),
nrow = length(list_of_features)
)
for(i in 1:length(list_of_features) ) {
for(j in 1:length(list_of_features) ) {
Out[i,j] <- sum(list_of_features[[i]] %in% list_of_features[[j]])/
length(unique(c(list_of_features[[i]], list_of_features[[j]])))
}
}
colnames(Out) <- rownames(Out) <- c("M3Drop", "HVG", "Cor", "PCA", "PCA2")8.4 伪时间分析
library(SingleCellExperiment)
library(TSCAN)
library(M3Drop)
library(monocle)
library(destiny)
library(SLICER)
library(ouija)
library(scater)
library(ggplot2)
library(ggthemes)
library(ggbeeswarm)
library(corrplot)
set.seed(1)在许多情况下,科学家正在研究细胞不断变化的过程。 这包括,例如,在发育阶段的分化过程:在刺激之后,细胞将从一种细胞类型变为另一种细胞类型。 理想情况下,我们希望监测单个细胞随时间的表达水平。然而,用scRNA-seq并不能做到,因为当提取RNA时细胞被裂解(破坏)。
相反,在多个时间点采样并获得基因表达谱的snapshot。 由于一些细胞将在分化过程中比其他细胞更快,因此每个snapshot包括处于不同发育状态的细胞。 使用统计方法沿着一个或多个轨迹对细胞进行排序,这些轨迹代表潜在的发育轨迹,这种排序被称为“伪时间”。
在本章中,我们考虑五种不同的工具:Monocle,TSCAN,destiny,SLICER和ouija,用于根据伪时间发育过程对细胞进行排序。 为了演示这些方法,我们使用小鼠胚胎发育的数据集(Deng et al. 2014)。该数据集由早期小鼠发育的10个不同时间点的268个细胞组成。 在这种情况下,不需要伪时间对齐,因为细胞标签提供关于发育轨迹的信息。 因此,细胞标签可以建立一个基准,以便评估和比较不同的方法。
Cannoodt等人最近的综述提供了来自单细胞转录组学的轨迹推断的各种计算方法的详细综述(Cannoodt, Saelens, and Saeys 2016)。 他们讨论了几种工具,但不幸的是,许多这些工具维护不善,或没有在R中实现。
Cannoodt等人包括:
- SCUBA - Matlab实现
- Wanderlust - Matlab (需要注册和下载)
- Wishbone - Python
- SLICER - R, 但是只能从GitHub安装
- SCOUP - C++ 命令行工具
- Waterfall - R, 附件中的R脚本
- Mpath - R包, GitHub安装,文档没有vignette/workflow
- Monocle - Bioconductor包
- TSCAN - Bioconductor包
然而只有两个讨论的工具(Monocle和TSCAN)满足开源软件黄金标准。
下图总结了不同工具的特征。
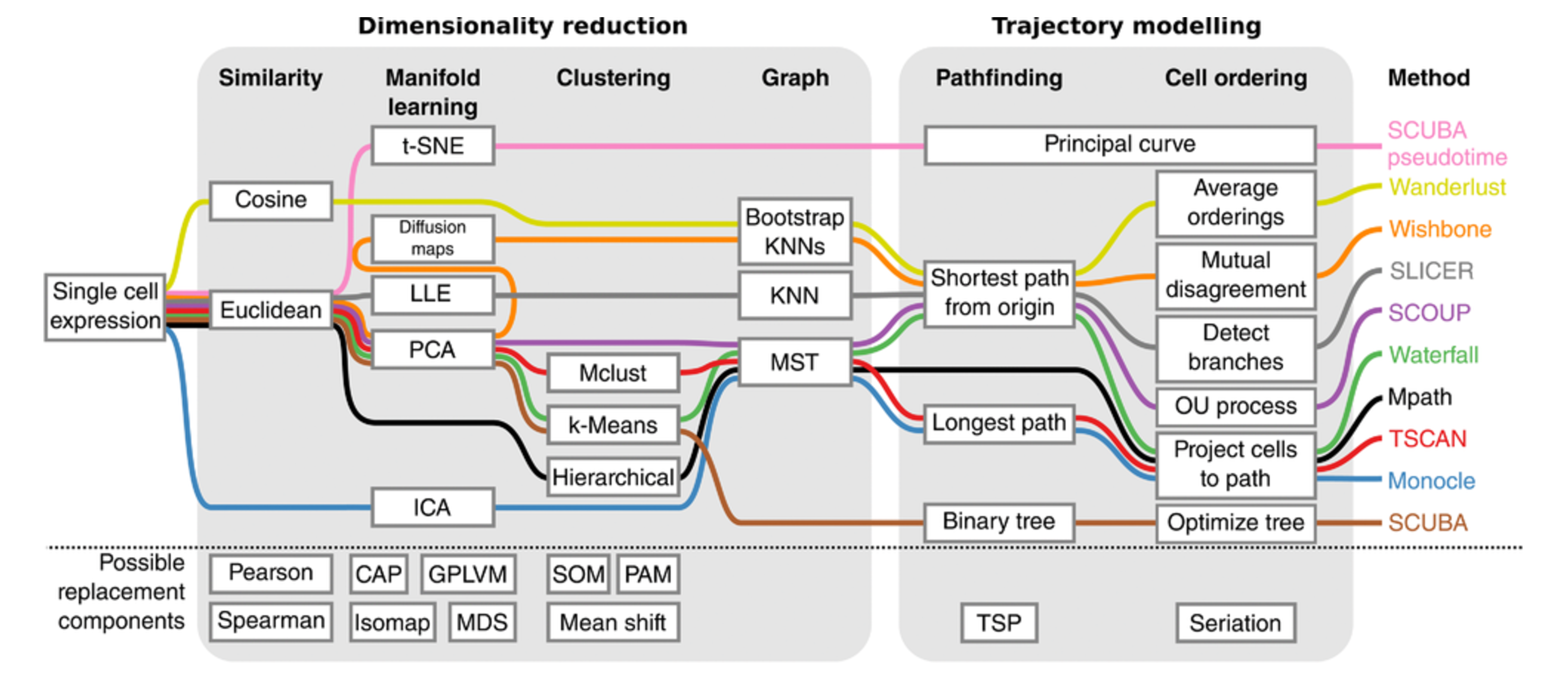
Figure 8.9: Descriptions of trajectory inference methods for single-cell transcriptomics data (Fig. 2 from Cannoodt et al, 2016).
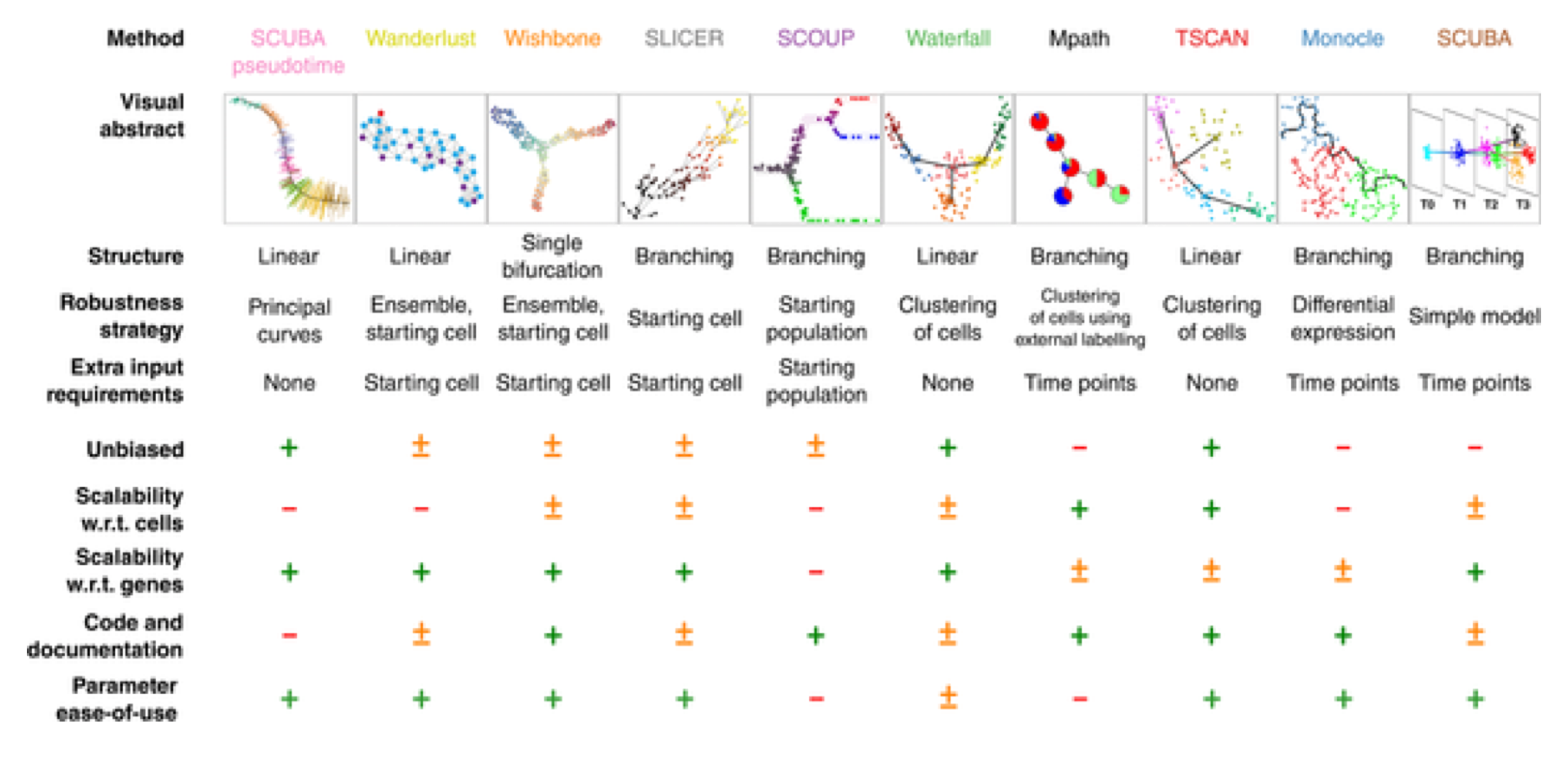
Figure 8.10: Characterization of trajectory inference methods for single-cell transcriptomics data (Fig. 3 from Cannoodt et al, 2016).
8.4.1 Deng数据初探
首先看看Deng data,但还没有应用复杂的伪时间方法。如下图所示,简单的PCA可以很好地显示这些数据中的结构。PCA分离的效果不错,除了囊胚细胞类型(“早期囊胚”, “中期囊胚”, “晚期囊胚”)混杂在一起。
deng_SCE <- readRDS("data/deng/deng-reads.rds")
deng_SCE$cell_type2 <- factor(
deng_SCE$cell_type2,
levels = c("zy", "early2cell", "mid2cell", "late2cell",
"4cell", "8cell", "16cell", "earlyblast",
"midblast", "lateblast")
)
cellLabels <- deng_SCE$cell_type2
deng <- counts(deng_SCE)
colnames(deng) <- cellLabels
deng_SCE <- runPCA(deng_SCE)
plotPCA(deng_SCE, colour_by = "cell_type2") PCA为评估不同的伪时间方法提供了基准。对于一个非常粗糙的伪时间分析,我们可以只取第一个主成分的坐标。
PCA为评估不同的伪时间方法提供了基准。对于一个非常粗糙的伪时间分析,我们可以只取第一个主成分的坐标。
deng_SCE$PC1 <- reducedDim(deng_SCE, "PCA")[,1]
ggplot(as.data.frame(colData(deng_SCE)), aes(x = PC1, y = cell_type2,
colour = cell_type2)) +
geom_quasirandom(groupOnX = FALSE) +
scale_color_tableau() + theme_classic() +
xlab("First principal component") + ylab("Timepoint") +
ggtitle("Cells ordered by first principal component")
如上图所示,PC1在发育时间段的早期和晚期都难以对细胞进行正确排序,但总的来说,按照发育时间对细胞排序效果不错。
定制的伪时间分析方法比粗糙引用PCA效果好吗?
8.4.2 TSCAN
TSCAN将聚类与伪时间分析相结合。首先,基于混合正态分布使用mclust聚类细胞。构建一个最小生成树来连接cluster。 连接最大数量cluster的分支是用于确定伪时间的主分支。
首先使用所有基因对细胞排序。
procdeng <- TSCAN::preprocess(deng)
colnames(procdeng) <- 1:ncol(deng)
dengclust <- TSCAN::exprmclust(procdeng, clusternum = 10)
TSCAN::plotmclust(dengclust)
dengorderTSCAN <- TSCAN::TSCANorder(dengclust, orderonly = FALSE)
pseudotime_order_tscan <- as.character(dengorderTSCAN$sample_name)
deng_SCE$pseudotime_order_tscan <- NA
deng_SCE$pseudotime_order_tscan[as.numeric(dengorderTSCAN$sample_name)] <-
dengorderTSCAN$Pseudotime令人沮丧的是,TSCAN仅为268细胞中221个细胞提供伪时间值,静默返回未指定细胞的缺失值。
检查哪些时间点分配给什么状态:
cellLabels[dengclust$clusterid == 10]
ggplot(as.data.frame(colData(deng_SCE)),
aes(x = pseudotime_order_tscan,
y = cell_type2, colour = cell_type2)) +
geom_quasirandom(groupOnX = FALSE) +
scale_color_tableau() + theme_classic() +
xlab("TSCAN pseudotime") + ylab("Timepoint") +
ggtitle("Cells ordered by TSCAN pseudotime")
TSCAN的发展轨迹是“错误的方式”,因为后来的伪时间值对应于早期时间点,反之亦然。 这本身并不是一个问题(通过翻转排序以获得伪时间的直观解释),但总的来说,TSCAN在此数据集上的性能优于PCA(并不奇怪,因为这是一种基于PCA的方法)
练习1 比较不同聚类数目的结果(clusternum).
8.4.3 monocle
Monocle跳过TSCAN的聚类阶段,并直接在细胞的降维尺度构建最小生成树以连接所有细胞。然后Monocle识别该树中最长的路径以确定伪时间。 Monocle可以识别发散轨迹(即一种细胞类型分化为两种不同的细胞类型)。每个分叉路径定义为单独的细胞状态。
不幸的是,Monocle在使用所有基因时不起作用,因此必须进行特征选择。首先,使用M3Drop:

运行monocle:
colnames(d) <- 1:ncol(d)
geneNames <- rownames(d)
rownames(d) <- 1:nrow(d)
pd <- data.frame(timepoint = cellLabels)
pd <- new("AnnotatedDataFrame", data=pd)
fd <- data.frame(gene_short_name = geneNames)
fd <- new("AnnotatedDataFrame", data=fd)
dCellData <- newCellDataSet(d, phenoData = pd, featureData = fd, expressionFamily = tobit())
dCellData <- setOrderingFilter(dCellData, which(geneNames %in% m3dGenes))
dCellData <- estimateSizeFactors(dCellData)
dCellDataSet <- reduceDimension(dCellData, pseudo_expr = 1)
dCellDataSet <- orderCells(dCellDataSet, reverse = FALSE)
plot_cell_trajectory(dCellDataSet)
# Store the ordering
pseudotime_monocle <-
data.frame(
Timepoint = phenoData(dCellDataSet)$timepoint,
pseudotime = phenoData(dCellDataSet)$Pseudotime,
State = phenoData(dCellDataSet)$State
)
rownames(pseudotime_monocle) <- 1:ncol(d)
pseudotime_order_monocle <-
rownames(pseudotime_monocle[order(pseudotime_monocle$pseudotime), ]) 将推断的伪时间与已知的采样时间点进行比较。
将推断的伪时间与已知的采样时间点进行比较。
deng_SCE$pseudotime_monocle <- pseudotime_monocle$pseudotime
ggplot(as.data.frame(colData(deng_SCE)),
aes(x = pseudotime_monocle,
y = cell_type2, colour = cell_type2)) +
geom_quasirandom(groupOnX = FALSE) +
scale_color_tableau() + theme_classic() +
xlab("monocle pseudotime") + ylab("Timepoint") +
ggtitle("Cells ordered by monocle pseudotime")
Monocle - 至少是默认设置 - 在这些数据上表现不佳。 “late2cell”与“zy”,“early2cell”和“mid2cell”细胞完全分离(尽管这些是正确排序的),并且“4cell”,“8cell”,“16cell”及其它囊胚期细胞完全没有分离。
8.4.4 Diffusion maps
Diffusion maps由 Ronald Coifman和Stephane Lafon引入,其基本思想是假设数据是来自扩散过程的样本。 该方法通过估计与数据相关的扩散算子的特征值和特征向量来推断低维流形。
Angerer et al将diffusion map概念应用于scRNA-seq数据的分析,创建 destiny的R包。
我们将在这里将第一扩散映射分量中的细胞的顺序作为“diffusion map pseudotime”。
deng <- logcounts(deng_SCE)
colnames(deng) <- cellLabels
dm <- DiffusionMap(t(deng))
tmp <- data.frame(DC1 = eigenvectors(dm)[,1],
DC2 = eigenvectors(dm)[,2],
Timepoint = deng_SCE$cell_type2)
ggplot(tmp, aes(x = DC1, y = DC2, colour = Timepoint)) +
geom_point() + scale_color_tableau() +
xlab("Diffusion component 1") +
ylab("Diffusion component 2") +
theme_classic()
deng_SCE$pseudotime_diffusionmap <- rank(eigenvectors(dm)[,1])
ggplot(as.data.frame(colData(deng_SCE)),
aes(x = pseudotime_diffusionmap,
y = cell_type2, colour = cell_type2)) +
geom_quasirandom(groupOnX = FALSE) +
scale_color_tableau() + theme_classic() +
xlab("Diffusion map pseudotime (first diffusion map component)") +
ylab("Timepoint") +
ggtitle("Cells ordered by diffusion map pseudotime")
与其他方法一样,使用destiny中的第一个扩散映射成分作为伪时间可以很好地排序早期时间点,但它无法很好区分后者。
练习2 通过考虑额外的特征向量,是否在较晚的时间点获得更好的分辨率? 练习3 如果只是用M3Drop识别的基因,顺序如何改变?
8.4.5 SLICER
SLICER方法是用于构建轨迹的算法,其描述在连续生物过程期间的基因表达变化,就像Monocle和TSCAN。 SLICER旨在捕获高度非线性基因表达变化,自动选择与过程相关的基因,并检测轨迹中的多个分支和环路特征(Welch, Hartemink, and Prins 2016)。SLICER R软件包可从GitHub获得,可以使用devtools安装。
使用SLICER中的select_genes函数自动选择用于构建细胞轨迹的基因。 该函数使用“neighbourhood variance”来识别在一组细胞中平滑变化而不是随机波动的基因。然后确定哪个“k”值(最近邻居的数量)产生最类似于轨迹的embedding。然后估计细胞的 locally linear embedding。
library("lle")
slicer_genes <- select_genes(t(deng))
k <- select_k(t(deng[slicer_genes,]), kmin = 30, kmax=60)
slicer_traj_lle <- lle(t(deng[slicer_genes,]), m = 2, k)$Y
reducedDim(deng_SCE, "LLE") <- slicer_traj_lle
plotReducedDim(deng_SCE, use_dimred = "LLE", colour_by = "cell_type2") +
xlab("LLE component 1") + ylab("LLE component 2") +
ggtitle("Locally linear embedding of cells from SLICER")
通过计算locally linear embedding,构建全连接的k-最近邻图。每个细胞用黄色圆圈表示,细胞ID蓝字位于中间。这里显示使用10个最近邻居计算的图表。这里SLICER似乎通过一个分支检测到一个主要轨迹。
slicer_traj_graph <- conn_knn_graph(slicer_traj_lle, 10)
plot(slicer_traj_graph, main = "Fully connected kNN graph from SLICER")
从该图可以congoing轨迹中起始/结束细胞的识别“极端”细胞。

定义起始细胞后,使用估计伪时间对细胞进行排序。
pseudotime_order_slicer <- cell_order(slicer_traj_graph, start)
branches <- assign_branches(slicer_traj_graph, start)
pseudotime_slicer <-
data.frame(
Timepoint = cellLabels,
pseudotime = NA,
State = branches
)
pseudotime_slicer$pseudotime[pseudotime_order_slicer] <-
1:length(pseudotime_order_slicer)
deng_SCE$pseudotime_slicer <- pseudotime_slicer$pseudotime将推断的伪时间与已知的采样时间点进行比较,SLICER本身不提供伪时间值,只是细胞的排序。
ggplot(as.data.frame(colData(deng_SCE)),
aes(x = pseudotime_slicer,
y = cell_type2, colour = cell_type2)) +
geom_quasirandom(groupOnX = FALSE) +
scale_color_tableau() + theme_classic() +
xlab("SLICER pseudotime (cell ordering)") +
ylab("Timepoint") +
theme_classic() 与之前的方法一样,SLICER对早期时间点进行正确的排序,但是其将“16cell”期置于“8cell”期之前,但是对于囊胚细胞提供了比许多早期方法更好的排序。
与之前的方法一样,SLICER对早期时间点进行正确的排序,但是其将“16cell”期置于“8cell”期之前,但是对于囊胚细胞提供了比许多早期方法更好的排序。
练习4 当k不同时,结果如何变化(比如k=5),如何在调用conn_knn_graph时改变最近邻数目?
练习5 当使用SLICER选择的另一组基因(比如M3Drop鉴定的基因),轨迹如何变化?
8.4.6 Ouija
Ouija采用了与迄今为所研究的伪时间估计方法不同的策略。 早期的方法都是“无监督的”,也就是说,除了可能选择informative genes之外,我们不提供任何关于期望某些基因或整个轨迹表现的先验信息。
相比之下,Ouija是一种概率框架,仅使用一小组marker基因来解释学习single-cell pseudotimes。 这个方法:
- 从少数标记基因中推断出pseudotimes,让您了解为什么pseudotimes从这些基因中学习出来;
- 为解释基因调控行为(如峰值时间或上调时间)提供参数估计(具有不确定性);
- 贝叶斯假设检验发现调控基因
- 识别亚稳态,即沿连续轨迹的离散细胞类型。
将向Ouija提供以下标记基因(以及高度表达的预计时间点):
- 早期时间点: Dazl, Rnf17, Sycp3, Nanog, Pou5f1, Fgf8, Egfr, Bmp5, Bmp15
- 中期时间点: Zscan4b, Foxa1, Prdm14, Sox21
- 晚期时间点: Creb3, Gpx4, Krt8, Elf5, Eomes, Cdx2, Tdgf1, Gdf3
使用Ouija,我们可以将基因建模为表现为单调上调或下调(称为开关行为),或基因短暂达到峰值的瞬态行为。 默认情况下,Ouija假设所有基因都表现出类似开关的行为(作者保证我们不要担心,如果我们弄错了,噪声模型意味着错误地指定瞬态基因,因为类似开关的影响很小)。
在这里,我们可以“作弊”,并检查我们选择的标记基因确实确定了分化过程的不同时间点。
ouija_markers_down <- c("Dazl", "Rnf17", "Sycp3", "Fgf8",
"Egfr", "Bmp5", "Bmp15", "Pou5f1")
ouija_markers_up <- c("Creb3", "Gpx4", "Krt8", "Elf5", "Cdx2",
"Tdgf1", "Gdf3", "Eomes")
ouija_markers_transient <- c("Zscan4b", "Foxa1", "Prdm14", "Sox21")
ouija_markers <- c(ouija_markers_down, ouija_markers_up,
ouija_markers_transient)
plotExpression(deng_SCE, ouija_markers, x = "cell_type2", colour_by = "cell_type2") +
theme(axis.text.x = element_text(angle = 60, hjust = 1)) 为了拟合pseudotimes,只需调用
为了拟合pseudotimes,只需调用ouija,传递预期的响应类型。 注意,如果没有提供响应类型,则默认情况下它们都被假定为类似开关。 Ouija的输入可以是非负表达值的cell-by-gene矩阵,也可以是ExpressionSet对象,或者SingleCellExperiment对象中选择logcounts值。
我们可以应用关于基因在分化过程中是上调还是下调的先验信息,并且还提供关于何时可能发生表达转换或表达峰值的先验信息。
使用下列拟合Ouija模型:
- Hamiltonian Monte Carlo (HMC) - MCMC推断,其中log-posterior梯度信息用于“引导”随机遍历参数空间,或
- Automatic Differentiation Variational Bayes (ADVI or simply VI) - 近似推断,其中最小化KL近似分布偏差。
一般而言,HMC将为所有参数提供更准确的推理和近似正确的后验方差。 然而,VB比HMC快几个数量级,虽然它可能低估了后验方差,但是Ouija的作者认为,通常情况下,其在发现后验pseudotimes和HMC效果相同。
为了帮助Ouija模型,我们为它提供了关于上调和下调基因的开关强度的先验信息。 通过将下调基因的开关强度设置为-10,将上调基因的开关强度设置为10,先验强度标准差为0.5,告诉模型我们对这些基因在分化过程中的预期行为充满信心。
options(mc.cores = parallel::detectCores())
response_type <- c(rep("switch", length(ouija_markers_down) +
length(ouija_markers_up)),
rep("transient", length(ouija_markers_transient)))
switch_strengths <- c(rep(-10, length(ouija_markers_down)),
rep(10, length(ouija_markers_up)))
switch_strength_sd <- c(rep(0.5, length(ouija_markers_down)),
rep(0.5, length(ouija_markers_up)))
garbage <- capture.output(
oui_vb <- ouija(deng_SCE[ouija_markers,],
single_cell_experiment_assay = "logcounts",
response_type = response_type,
switch_strengths = switch_strengths,
switch_strength_sd = switch_strength_sd,
inference_type = "vb")
)
print(oui_vb)使用plot_expression函数绘制伪时间基因表达以及平均函数(sigmoid或高斯瞬态函数)的最大后验(MAP)估计。

使用plot_switch_times和plot_transient_times函数,在轨迹基因调控行为发生时,以switch时间或峰值时间(对于类似开关或瞬态基因)的形式进行可视化:

 使用一致性矩阵识别亚稳态。
使用一致性矩阵识别亚稳态。

map_pst <- map_pseudotime(oui_vb)
ouija_pseudotime <- data.frame(map_pst, cell_classifications)
ggplot(ouija_pseudotime, aes(x = map_pst, y = cell_classifications)) +
geom_point() +
xlab("MAP pseudotime") +
ylab("Cell classification")
deng_SCE$pseudotime_ouija <- ouija_pseudotime$map_pst
deng_SCE$ouija_cell_class <- ouija_pseudotime$cell_classifications
ggplot(as.data.frame(colData(deng_SCE)),
aes(x = pseudotime_ouija,
y = cell_type2, colour = cell_type2)) +
geom_quasirandom(groupOnX = FALSE) +
scale_color_tableau() + theme_classic() +
xlab("Ouija pseudotime") +
ylab("Timepoint") +
theme_classic()
虽然Ouija对标记基因的选择和提供的先验信息敏感,但Ouija在细胞的排序方面表现相当不错。 如果选择不同的标记基因或更改先验信息,结果会如何变化?
Ouija识别四种亚稳态,将其注释为“zygote/2cell”, “4/8/16 cell”, “blast1” and “blast2”。
ggplot(as.data.frame(colData(deng_SCE)),
aes(x = as.factor(ouija_cell_class),
y = pseudotime_ouija, colour = cell_type2)) +
geom_boxplot() +
coord_flip() +
scale_color_tableau() + theme_classic() +
xlab("Ouija cell classification") +
ylab("Ouija pseudotime") +
theme_classic() 一个常见的分析是基因的调节顺序。 例如,基因A在基因B之前是否上调? 基因C在基因D下调前是否达到峰值? Ouija根据贝叶斯假设检验来回答这些问题,该检验调控时间的差异(switch时间或峰值时间)是否和0有显著差异。
一个常见的分析是基因的调节顺序。 例如,基因A在基因B之前是否上调? 基因C在基因D下调前是否达到峰值? Ouija根据贝叶斯假设检验来回答这些问题,该检验调控时间的差异(switch时间或峰值时间)是否和0有显著差异。
gene_regs <- gene_regulation(oui_vb)
head(gene_regs)
## # A tibble: 6 x 7
## # Groups: label, gene_A [6]
## label gene_A gene_B mean_difference lower_95 upper_95 significant
## <chr> <chr> <chr> <dbl> <dbl> <dbl> <lgl>
## 1 Bmp15 - Cdx2 Bmp15 Cdx2 -0.0658 -1.17e-1 -0.0136 TRUE
## 2 Bmp15 - Creb3 Bmp15 Creb3 0.266 1.96e-1 0.321 TRUE
## 3 Bmp15 - Elf5 Bmp15 Elf5 -0.665 -7.03e-1 -0.622 TRUE
## 4 Bmp15 - Eomes Bmp15 Eomes 0.0765 -1.30e-2 0.150 FALSE
## 5 Bmp15 - Foxa1 Bmp15 Foxa1 -0.0157 -4.95e-2 0.0128 FALSE
## 6 Bmp15 - Gdf3 Bmp15 Gdf3 0.0592 2.06e-4 0.114 TRUE可以从Ouija的基因调控输出中得出什么结论?
尝试HMC推断,查看Ouija结果是否变化?
8.4.7 方法比较
如何比较TSCAN,Monocle,Diffusion Map,SLICER和Ouija推断出的轨迹?
TSCAN和Diffusion Map方法轨迹“方向错误”,比对之前先对其进行调整。
df_pseudotime <- as.data.frame(
colData(deng_SCE)[, grep("pseudotime", colnames(colData(deng_SCE)))]
)
colnames(df_pseudotime) <- gsub("pseudotime_", "",
colnames(df_pseudotime))
df_pseudotime$PC1 <- deng_SCE$PC1
df_pseudotime$order_tscan <- -df_pseudotime$order_tscan
df_pseudotime$diffusionmap <- -df_pseudotime$diffusionmap
corrplot.mixed(cor(df_pseudotime, use = "na.or.complete"),
order = "hclust", tl.col = "black",
main = "Correlation matrix for pseudotime results",
mar = c(0, 0, 3.1, 0))
上图所示,Ouija,TSCAN和SLICER都提供了与PC1类似且强相关的轨迹。Diffusion Map与这些方法的相关性较低,而Monocle给出了非常不同的结果。
练习6: 将destiny和SLICER与TSCAN,Monocle和Ouija进行更深入的比较。区别在哪里?
8.4.8 Expression of genes through time
每个包可以通过伪时间显示基因表达。检查单个基因非常有助于鉴定在分化过程中起重要作用的基因。使用Rhoa基因进行演示。
我们已经将使用所有方法计算的伪时间值添加到SCE对象的colData中。scater软件包的绘图功能可用于研究基因表达,细胞群和pseudotime的关系。 这对于不提供绘图功能的SLICER等软件包非常有用。
主成分
plotExpression(deng_SCE, "Rhoa", x = "PC1",
colour_by = "cell_type2", show_violin = FALSE,
show_smooth = TRUE) TSCAN
TSCAN
plotExpression(deng_SCE, "Rhoa", x = "pseudotime_order_tscan",
colour_by = "cell_type2", show_violin = FALSE,
show_smooth = TRUE) Monocle
Monocle
plotExpression(deng_SCE, "Rhoa", x = "pseudotime_monocle",
colour_by = "cell_type2", show_violin = FALSE,
show_smooth = TRUE) Diffusion Map
Diffusion Map
plotExpression(deng_SCE, "Rhoa", x = "pseudotime_diffusionmap",
colour_by = "cell_type2", show_violin = FALSE,
show_smooth = TRUE)
SLICER
plotExpression(deng_SCE, "Rhoa", x = "pseudotime_slicer",
colour_by = "cell_type2", show_violin = FALSE,
show_smooth = TRUE) Ouija
Ouija
plotExpression(deng_SCE, "Rhoa", x = "pseudotime_ouija",
colour_by = "cell_type2", show_violin = FALSE,
show_smooth = TRUE)
这些方法中有多少优于使用第一主成分表示伪时间?
练习7: 使用一部基因比如Brennecke_getVariableGenes()得到的HVG重复上面练习。
8.5 Imputation
library(scImpute)
library(SC3)
library(scater)
library(SingleCellExperiment)
library(mclust)
library(DrImpute)
library(Rmagic)
set.seed(1234567)如前所述,分析scRNA-seq数据时的主要挑战之一是存在零或dropout。Dropouts可能由于以下原因:
- 基因不在细胞中表达,因此没有转录物
- 基因表达,但由于某些原因,转录本在测序前丢失
- 基因表达并捕获转录物并转化为cDNA,但测序深度低。
因此,dropout可能是实验缺陷,如果是这种情况,希望提供计算校正。一种策略是将从表达矩阵插补缺失值,为了能够插补基因表达值,必须有一个基础模型。由于不知道哪些dropout是技术原因,哪些对应于真实缺失,因此插补是一项艰巨的挑战,并且倾向于在下游分析中产生 假阳性结果。
目前有很多插值的方法,再次我们考虑三种运行速度快而且发表的方法: MAGIC (Dijk et al. 2017), DrImpute and scImpute (Li and Li 2017).
DrImpute和scImpute都使用模型来确定哪些零值是技术原因造成的,并且对这些值进行插补。二者都使用聚类来识别具有同源表达的一组细胞。 DrImpute插补cluster中细胞表达不一致为0的值。然而,scImpute使用零膨胀的正态分布拟合对数归一化的表达值并估算inflated零值。
8.5.1 scImpute
为测试scImpute,使用默认参数应用于Deng数据集。scImpute将.csv或.txt文件作为输入:
deng <- readRDS("data/deng/deng-reads.rds")
write.csv(counts(deng), "deng.csv")
scimpute(
count_path = "deng.csv",
infile = "csv",
outfile = "txt",
out_dir = "./",
Kcluster = 10,
ncores = 2
)通过PCA图来比较结果和原始数据
res <- read.table("scimpute_count.txt")
colnames(res) <- NULL
res <- SingleCellExperiment(
assays = list(logcounts = log2(as.matrix(res) + 1)),
colData = colData(deng)
)
rowData(res)$feature_symbol <- rowData(deng)$feature_symbol
plotPCA(
res,
colour_by = "cell_type2"
)
比较结果与章节8.2的原始数剧。最显著的差异是什么?
检查特定基因的表达,观察插补对表达分布的影响。


为评价插补的效果,使用SC3对插补后的矩阵进行聚类。
res <- sc3_estimate_k(res)
metadata(res)$sc3$k_estimation
## [1] 6
res <- sc3(res, ks = 10, n_cores = 1, gene_filter = FALSE)
adjustedRandIndex(colData(deng)$cell_type2, colData(res)$sc3_10_clusters)
## [1] 0.5062983
plotPCA(
res,
colour_by = "sc3_10_clusters"
)
练习: 基于PCA和聚类结果,使用scImpute对Deng数据集进行插补效果好吗?
8.5.2 DrImpute
使用DrImpute进行同样的操作。DrImpute在R中直接运行对数标准化表达矩阵,使用scater生成此矩阵,然后运行DrImpute。 与scImpute不同,DrImpute使用两个不同的相关距离来考虑跨越一系列ks的一致性插补:
deng <- normalize(deng)
res <- DrImpute(deng@assays[["logcounts"]], ks=8:12)
colnames(res) <- colnames(deng)
rownames(res) <- rownames(deng)
res <- SingleCellExperiment(
assays = list(logcounts = as.matrix(res)),
colData = colData(deng)
)
rowData(res)$feature_symbol <- rowData(deng)$feature_symbol
plotPCA(
res,
colour_by = "cell_type2"
)
 练习: 检查DrImpute矩阵的sc3聚类,
练习: 检查DrImpute矩阵的sc3聚类,DrImpute适合对Deng数据集进行插补吗?
8.5.3 MAGIC
(由于技术原因,本章作为练习)
MAGIC是一个python包,但是作者提供了一个R包封装,所以它可以从R无缝地运行。
与scImpute和DrImpute不同,MAGIC可以smooth整个数据集。它会对零值进行插补,但也会smooth非零值,以进一步扩大数据集中的结构。 由于它基于扩散过程,因此特别增强了数据集中类似轨迹的结构,与scImpute和DrImpute相反,后者假设数据具有类似cluster的结构。
比对结果与章节8.2的原始数据。显著差异是什么?
为评价插补的效果,使用SC3对插补后的矩阵进行聚类。
练习: MAGIC包含2个影响插补水平的参数:t 和 k,增大或减小这些参数,结果如何?(提示:尝试t=1, t=10, k=2, k=50)
练习: 基于PCA和聚类分析的scImpute和MAGIC有什么区别?哪一个更好用?
8.6 差异表达分析
8.6.1 Bulk RNA-seq
bulk RNA-seq数据最常见的分析类型之一是鉴定差异表达的基因。通过比较在两种条件下变化的基因,例如 突变体和野生型或刺激和未刺激的,寻找背后的分子机制。
用于bulk RNA-seq差异表达分析有几种不同的方法,比如 DESeq2和 edgeR,而且有大量的 数据集,其中RNA-seq数据被RT-qPCR验证。这些数据可以对差异表达分析的算法进行基准测试。现有的证据表明算法表现不错。
8.6.2 Single cell RNA-seq
与bulk RNA-seq相反,在scRNA-seq中,通常没有一组确定的实验条件。如前一章(8.2)所示,通过无监督的聚类方法来识别细胞群体,然后通过比较各群体之间的差异(如SC3的Kruskal-Wallis检验),或成对比较cluster中基因表达,找到差异表达的基因。 在下一章中,我们将主要考虑为成对比较开发的工具。
8.6.3 分布的差异
与bulk RNA-seq不同,在单细胞实验中,每个group有大量的样品(即细胞)。 因此,利用每组中表达值的完整分布来识别组间的差异,而不是向bulk RNA-seq中仅仅比较平均表达。
主要有两种方法比较分布。首先,可以使用现有的统计模型/分布拟合到每个组中的表达,然后检验每个模型的参数差异,或者允许特定参数不同,模型是否拟合地更好。例如在章节7.10,使用edgeR检验在不同批次中允许平均表达不同是否显著提高数据的负二项模型的拟合。
或者,使用非参数检验,该检验不假设表达值服从任何特定分布,例如, Kolmogorov-Smirnov test (KS-test)。 非参数测试通常将观察到的表达值转换为rank并检验一组的rank分布是否与另一组的rank分布显著不同。然而,一些非参数方法不适用存在大量tied values,例如单细胞RNA-seq表达数据中的dropout的情况。 此外,如果参数检验的条件成立,那么它通常比非参数测试更强大。
8.6.4 scRNA-seq数据模型
最常用的RNA-seq数据模型是负二项分布模型:
set.seed(1)
hist(
rnbinom(
1000,
mu = 10,
size = 100),
col = "grey50",
xlab = "Read Counts",
main = "Negative Binomial"
)
Figure 8.11: Negative Binomial distribution of read counts for a single gene across 1000 cells
均值: \(\mu = mu\)
方差: \(\sigma^2 = mu + mu^2/size\)
其有两个参数,平均表达值(\(\mu\))和离散程度(dispersion),离散程度与方差负相关。负二项分布模型很好地拟合了bulk RNA-seq数据,并且应用于大多数统计方法。此外,它也很好地你好了UMI数据的molecule coutns分布(Grun et al. 2014, Islam et al. 2011)。
然而由于相对于非零read counts的高dropout率,原始负二项分布模型不适合全长转录本数据。对于这种类型的数据,已经提出了各种零膨胀负二项模型,比如 MAST, SCDE。
d <- 0.5;
counts <- rnbinom(
1000,
mu = 10,
size = 100
)
counts[runif(1000) < d] <- 0
hist(
counts,
col = "grey50",
xlab = "Read Counts",
main = "Zero-inflated NB"
)
Figure 8.12: Zero-inflated Negative Binomial distribution
均值: \(\mu = mu \cdot (1 - d)\)
方差: \(\sigma^2 = \mu \cdot (1-d) \cdot (1 + d \cdot \mu + \mu / size)\)
这个模型为dropout引入新的参数\(d\)到负二项分布模型,如第19章中所看到的,基因的dropout率与基因的平均表达密切相关。 不同的零膨胀负二项模型使用mu和d之间的不同关系,并且一些可以使\(\mu\)和\(d\)拟合每个基因的表达。
最后,一些方法使用Poisson-Beta分布,该分布基于转录爆发的机制模型。 这个模型有很强的实验支持( Kim and Marioni, 2013),它较好地拟合scRNA-seq数据,但它比负二项模型不容易使用,而且现有的方法交少。
a <- 0.1
b <- 0.1
g <- 100
lambdas <- rbeta(1000, a, b)
counts <- sapply(g*lambdas, function(l) {rpois(1, lambda = l)})
hist(
counts,
col = "grey50",
xlab = "Read Counts",
main = "Poisson-Beta"
) 均值:
\(\mu = g \cdot a / (a + b)\)
均值:
\(\mu = g \cdot a / (a + b)\)
方差: \(\sigma^2 = g^2 \cdot a \cdot b/((a + b + 1) \cdot (a + b)^2)\)
该模型使用三个参数:\(a\)转录激活率; \(b\)转录抑制率; 和\(g\)转录激活状态时转录本产生的速率。 差异表达方法可以检验每个参数的组间差异或仅一个(通常是\(g\))。
所有这些模型可以进一步扩展来明确地解释基因表达差异的其他来源,例如批次效应或文库深度,这取决于特定的DE算法。
练习: 改变每个分布的参数,探索它们如何影响基因表达的分布。Poisson-Beta和Negative Binomial模型相似处在哪里?
8.7 差异表达分析实战
8.7.1 介绍
为了测试不同的单细胞差异表达方法,我们使用第7-17章的Blischak数据集。对于该实验,除了单细胞数据之外,还产生每个细胞系的bulk RNA-seq数据。 使用标准方法分别在bulk RNA-seq和scRNA-seq鉴定差异表达基因,并用bulk RNA-seq结果评估单细胞方法准确性。为了节省时间,我们预先计算了这些。 可以运行以下命令来加载这些数据。
DE <- read.table("data/tung/TPs.txt")
notDE <- read.table("data/tung/TNs.txt")
GroundTruth <- list(
DE = as.character(unlist(DE)),
notDE = as.character(unlist(notDE))
)比较NA19101到NA19239的基准已经产生,下面加载相应的单细胞数据:
molecules <- read.table("data/tung/molecules.txt", sep = "\t")
anno <- read.table("data/tung/annotation.txt", sep = "\t", header = TRUE)
keep <- anno[,1] == "NA19101" | anno[,1] == "NA19239"
data <- molecules[,keep]
group <- anno[keep,1]
batch <- anno[keep,4]
# remove genes that aren't expressed in at least 6 cells
gkeep <- rowSums(data > 0) > 5;
counts <- data[gkeep,]
# Library size normalization
lib_size = colSums(counts)
norm <- t(t(counts)/lib_size * median(lib_size))
# Variant of CPM for datasets with library sizes of fewer than 1 mil molecules现在比较各种单细胞差异表达分析方法。请注意,这里只运行R语言环境并且运行速度相对较快的方法。
8.7.2 Kolmogorov-Smirnov test
最容易使用的检验类型是非参数测试。最常用的非参数检验是 Kolmogorov-Smirnov test (KS-test),可以用它来比较两个个体中每个基因的分布。
KS检验量化了两个群体中每个基因表达的经验累积分布之间的距离。它对平均表达值的变化和方差的变化很敏感。 然而,它假设数据是连续的,并且当数据包含大量相同的值(例如,0)时可能表现不佳。 KS检验的另一个问题是它对于大样本量可能非常敏感,因此即使差异的幅度非常小,它也可能结果为显著。
)](figures/KS2_Example.png)
Figure 8.13: Illustration of the two-sample Kolmogorov–Smirnov statistic. Red and blue lines each correspond to an empirical distribution function, and the black arrow is the two-sample KS statistic. (taken from here)
运行KS检验:
pVals <- apply(
norm, 1, function(x) {
ks.test(
x[group == "NA19101"],
x[group == "NA19239"]
)$p.value
}
)
# multiple testing correction
pVals <- p.adjust(pVals, method = "fdr")此代码将函数“appy”到表达矩阵的每一行(由1指定)。函数只返回ks.test输出的p.value。 我们现在可以考虑通过KS检验检测到多少true positive和true negative DE基因.
8.7.2.1 评价准确率
sigDE <- names(pVals)[pVals < 0.05]
length(sigDE)
## [1] 5095
# Number of KS-DE genes
sum(GroundTruth$DE %in% sigDE)
## [1] 792
# Number of KS-DE genes that are true DE genes
sum(GroundTruth$notDE %in% sigDE)
## [1] 3190
# Number of KS-DE genes that are truly not-DE通过KS检验将基准中true negative基因识别为DE(假阳性),但这可能是由于大量的f非DE基因。通常将这些计数归一化为真阳性率(TPR), TP/(TP + FN)和假阳性率 (FPR), FP/(FP+TP)。
tp <- sum(GroundTruth$DE %in% sigDE)
fp <- sum(GroundTruth$notDE %in% sigDE)
tn <- sum(GroundTruth$notDE %in% names(pVals)[pVals >= 0.05])
fn <- sum(GroundTruth$DE %in% names(pVals)[pVals >= 0.05])
tpr <- tp/(tp + fn)
fpr <- fp/(fp + tn)
cat(c(tpr, fpr))
## 0.7346939 0.2944706TPR大于FPR,表明KS检验识别出差异表达基因。
目前为止,我们只评估了单个显著性阈值的性能。通常,可以改变阈值并评估一系列值的性能。 然后将其绘制为ROC(receiver-operating-characteristic curve)曲线,并且计算ROC曲线下的面积AUC。我们将使用ROCR包来绘图。
# Only consider genes for which we know the ground truth
pVals <- pVals[names(pVals) %in% GroundTruth$DE |
names(pVals) %in% GroundTruth$notDE]
truth <- rep(1, times = length(pVals));
truth[names(pVals) %in% GroundTruth$DE] = 0;
pred <- ROCR::prediction(pVals, truth)
perf <- ROCR::performance(pred, "tpr", "fpr")
ROCR::plot(perf)
Figure 8.14: ROC curve for KS-test.
最后,为了便于比较其他DE方法,将这段代码放入一个函数中,这样就不需要重复它:
DE_Quality_AUC <- function(pVals) {
pVals <- pVals[names(pVals) %in% GroundTruth$DE |
names(pVals) %in% GroundTruth$notDE]
truth <- rep(1, times = length(pVals));
truth[names(pVals) %in% GroundTruth$DE] = 0;
pred <- ROCR::prediction(pVals, truth)
perf <- ROCR::performance(pred, "tpr", "fpr")
ROCR::plot(perf)
aucObj <- ROCR::performance(pred, "auc")
return(aucObj@y.values[[1]])
}8.7.3 Wilcox/Mann-Whitney-U Test
The Wilcox-rank-sum检验是另一种非参数检验,检验一组中的值是否大于/小于另一组中的值。因此,它通常被认为是检验两组间表达值中位数差异; 而KS检验对表达值分布的任何变化都很敏感。
pVals <- apply(
norm, 1, function(x) {
wilcox.test(
x[group == "NA19101"],
x[group == "NA19239"]
)$p.value
}
)
# multiple testing correction
pVals <- p.adjust(pVals, method = "fdr")
DE_Quality_AUC(pVals)
## [1] 0.8320326
Figure 8.15: ROC curve for Wilcox test.
8.7.4 edgeR
我们已经在章节7.10中使用了edgeR来计算差异表达。 edgeR基于基因表达的负二项式模型,并使用广义线性模型(GLM),使我们能够将其他因素(例如批次)包含到模型中。
dge <- DGEList(
counts = counts,
norm.factors = rep(1, length(counts[1,])),
group = group
)
group_edgeR <- factor(group)
design <- model.matrix(~ group_edgeR)
dge <- estimateDisp(dge, design = design, trend.method = "none")
fit <- glmFit(dge, design)
res <- glmLRT(fit)
pVals <- res$table[,4]
names(pVals) <- rownames(res$table)
pVals <- p.adjust(pVals, method = "fdr")
DE_Quality_AUC(pVals)
## [1] 0.8466764
Figure 8.16: ROC curve for edgeR.
8.7.5 Monocle
Monocle可以使用几种不同的DE模型。 对于count数据,它建议使用负二项模型(negbinomial.size)。对于标准化数据,对其进行对数变换使用正态分布(gaussianff)。 与edgeR类似,此方法使用GLM框架,因此理论上可以考虑批次效应,但实际上,如果包含批次,模型将不适用此数据集。
pd <- data.frame(group = group, batch = batch)
rownames(pd) <- colnames(counts)
pd <- new("AnnotatedDataFrame", data = pd)
Obj <- newCellDataSet(
as.matrix(counts),
phenoData = pd,
expressionFamily = negbinomial.size()
)
Obj <- estimateSizeFactors(Obj)
Obj <- estimateDispersions(Obj)
res <- differentialGeneTest(Obj, fullModelFormulaStr = "~group")
pVals <- res[,3]
names(pVals) <- rownames(res)
pVals <- p.adjust(pVals, method = "fdr")
DE_Quality_AUC(pVals)
## [1] 0.8252662
Figure 8.17: ROC curve for Monocle.
练习: 比较使用负二项式模型结果和对数变换使用正态/高斯模型(gaussianff())模型结果。
Answer:
pd <- data.frame(group = group, batch = batch)
rownames(pd) <- colnames(norm)
pd <- new("AnnotatedDataFrame", data = pd)
Obj_log <- newCellDataSet(
as.matrix(log(norm + 1) / log(2)),
phenoData = pd,
expressionFamily = gaussianff()
)
Obj_log <- estimateSizeFactors(Obj_log)
# Obj_log <- estimateDispersions(Obj_log)
res <- differentialGeneTest(Obj_log, fullModelFormulaStr = "~group")
pVals <- res[,3]
names(pVals) <- rownames(res)
pVals <- p.adjust(pVals, method = "fdr")
DE_Quality_AUC(pVals)
## [1] 0.8294642
Figure 8.18: ROC curve for Monocle-gaussian.
8.7.6 MAST
MAST基于零膨胀负二项模型。 它使用hurdle模型检验差异表达,组合基因表达的离散(0对非0)检验和连续(非零值)检验。同样,其使用线性建模框架来考虑复杂模型。
log_counts <- log(counts + 1) / log(2)
fData <- data.frame(names = rownames(log_counts))
rownames(fData) <- rownames(log_counts);
cData <- data.frame(cond = group)
rownames(cData) <- colnames(log_counts)
obj <- FromMatrix(as.matrix(log_counts), cData, fData)
colData(obj)$cngeneson <- scale(colSums(assay(obj) > 0))
cond <- factor(colData(obj)$cond)
# Model expression as function of condition & number of detected genes
zlmCond <- zlm.SingleCellAssay(~ cond + cngeneson, obj)
summaryCond <- summary(zlmCond, doLRT = "condNA19101")
summaryDt <- summaryCond$datatable
summaryDt <- as.data.frame(summaryDt)
pVals <- unlist(summaryDt[summaryDt$component == "H",4]) # H = hurdle model
names(pVals) <- unlist(summaryDt[summaryDt$component == "H",1])
pVals <- p.adjust(pVals, method = "fdr")
DE_Quality_AUC(pVals)
## [1] 0.8284046
Figure 8.19: ROC curve for MAST.
8.7.7 Slow method(>1h)
这些方法今天运行速度太慢,但鼓励您自己尝试。
8.7.7.1 BPSC
BPSC使用单细胞基因表达的Poisson-Beta模型,并将与广义线性模型相结合。 BPSC将一个或多个组与参考组(“Control”)进行比较,并且可以包括其他因素,例如模型中的批次效应。
library(BPSC)
bpsc_data <- norm[,batch=="NA19101.r1" | batch=="NA19239.r1"]
bpsc_group = group[batch=="NA19101.r1" | batch=="NA19239.r1"]
control_cells <- which(bpsc_group == "NA19101")
design <- model.matrix(~bpsc_group)
coef=2 # group label
res=BPglm(data=bpsc_data, controlIds=control_cells, design=design, coef=coef,
estIntPar=FALSE, useParallel = FALSE)
pVals = res$PVAL
pVals <- p.adjust(pVals, method = "fdr")
DE_Quality_AUC(pVals)8.7.7.2 SCDE
SCDE是单细胞特异性差异表达分析方法。它使用贝叶斯统计量将零膨胀负二项式模型拟合表达数据。 以下用法检验各组间基因的平均表达差异,但最近的版本包括检验平均表达差异或一组基因的离散程度,通常代表一条通路。
library(scde)
cnts <- apply(
counts,
2,
function(x) {
storage.mode(x) <- 'integer'
return(x)
}
)
names(group) <- 1:length(group)
colnames(cnts) <- 1:length(group)
o.ifm <- scde::scde.error.models(
counts = cnts,
groups = group,
n.cores = 1,
threshold.segmentation = TRUE,
save.crossfit.plots = FALSE,
save.model.plots = FALSE,
verbose = 0,
min.size.entries = 2
)
priors <- scde::scde.expression.prior(
models = o.ifm,
counts = cnts,
length.out = 400,
show.plot = FALSE
)
resSCDE <- scde::scde.expression.difference(
o.ifm,
cnts,
priors,
groups = group,
n.randomizations = 100,
n.cores = 1,
verbose = 0
)
# Convert Z-scores into 2-tailed p-values
pVals <- pnorm(abs(resSCDE$cZ), lower.tail = FALSE) * 2
DE_Quality_AUC(pVals)8.8 比较/组合scRNA-seq数据集
8.8.1 介绍
随着scRNA-seq数据集越来越多,进行merged_seurat比较是关键。比较scRNA-Seq数据集有两种主要方法。 第一种方法是“label-centric”,其通过比较单个细胞或一组细胞识别数据集间相同的细胞类型/状态。另一种方法是“cross-dataset normalization”,试图去除特定实验的技术/生物效应,使得组合联合分析来自多个实验的数据。
label-centric方法可以与高置信度细胞注释的数据集一起使用,例如,人类细胞图谱(HCA)(Regev et al. 2017)或Tabula Muris (Consortium and others 2018)。一旦这些项目完成,将新样本的细胞或cluster投影到该参考图谱上以识别组织成分或识别细胞类型。 从概念上讲,这种预测类似于流行的BLAST方法(Altschul et al. 1990),这使得可以在数据库中快速找到最接近的匹配,用于新鉴定的核苷酸或氨基酸序列。 label-centric方法还可用于比较由不同实验室收集的相似生物来源的数据集,以确保注释和分析是一致的。
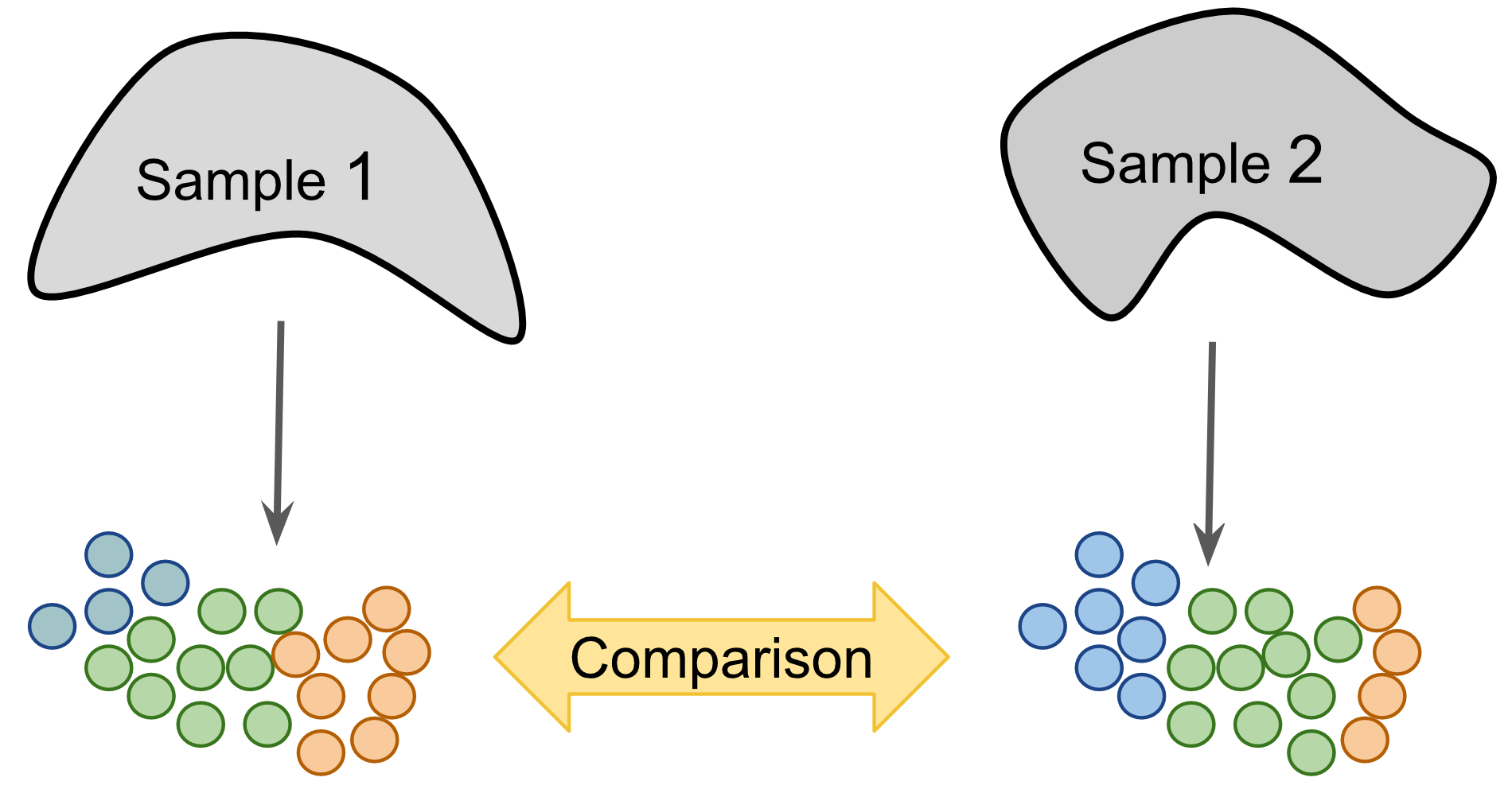
Figure 8.20: Label-centric dataset comparison can be used to compare the annotations of two different samples.
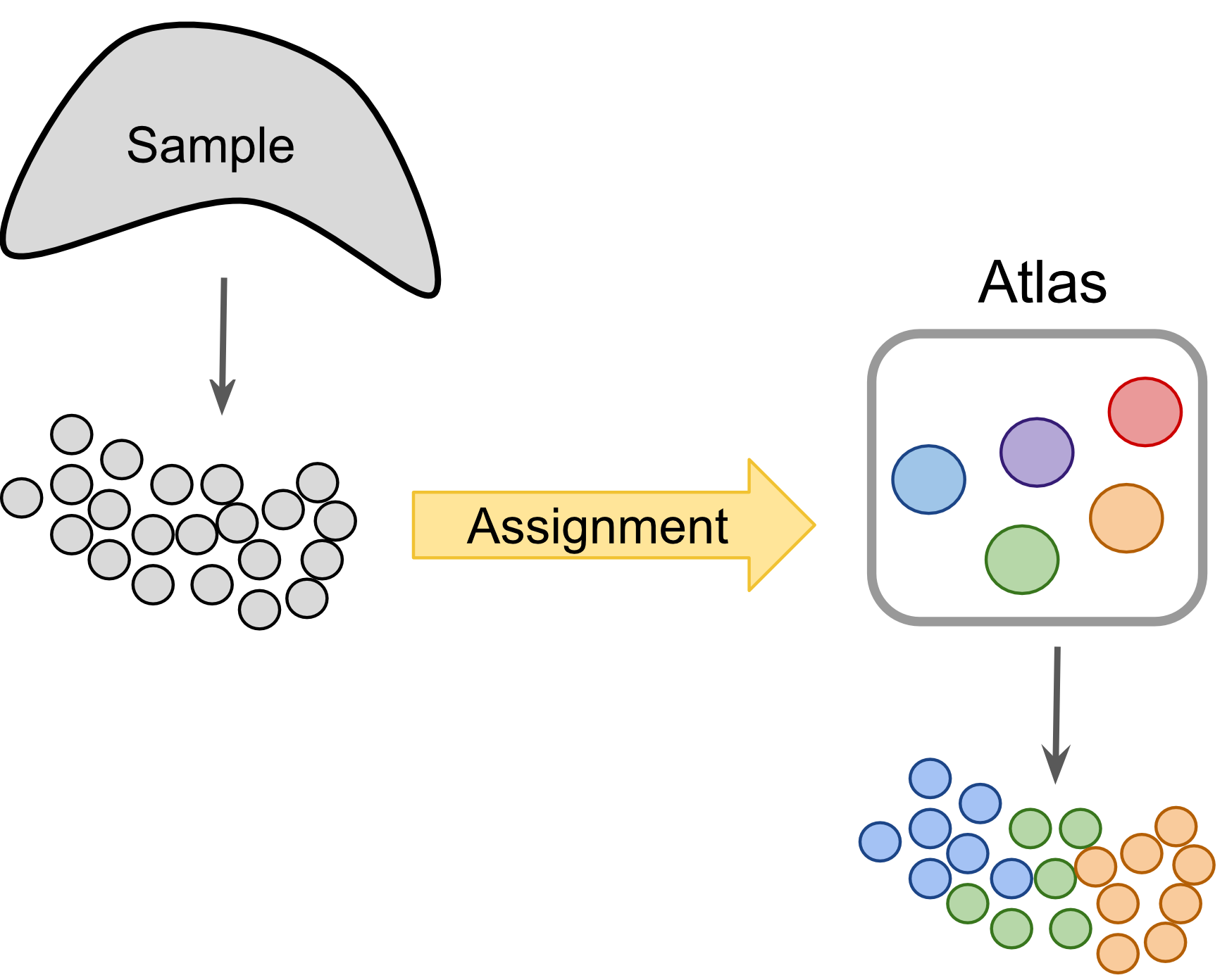
Figure 8.21: Label-centric dataset comparison can project cells from a new experiment onto an annotated reference.
cross-dataset normalization方法也可用于比较相似生物来源的数据集,不像label-centric方法,它可以实现多个数据集的联合分析,以便于更可靠地识别稀有细胞类型,其可能在每个个体中过于稀疏地采样。然而,cross-dataset normalization不适用于非常大且不同的reference,因为它假设每个数据集中的生物变异性的重要部分与其他数据集重叠。
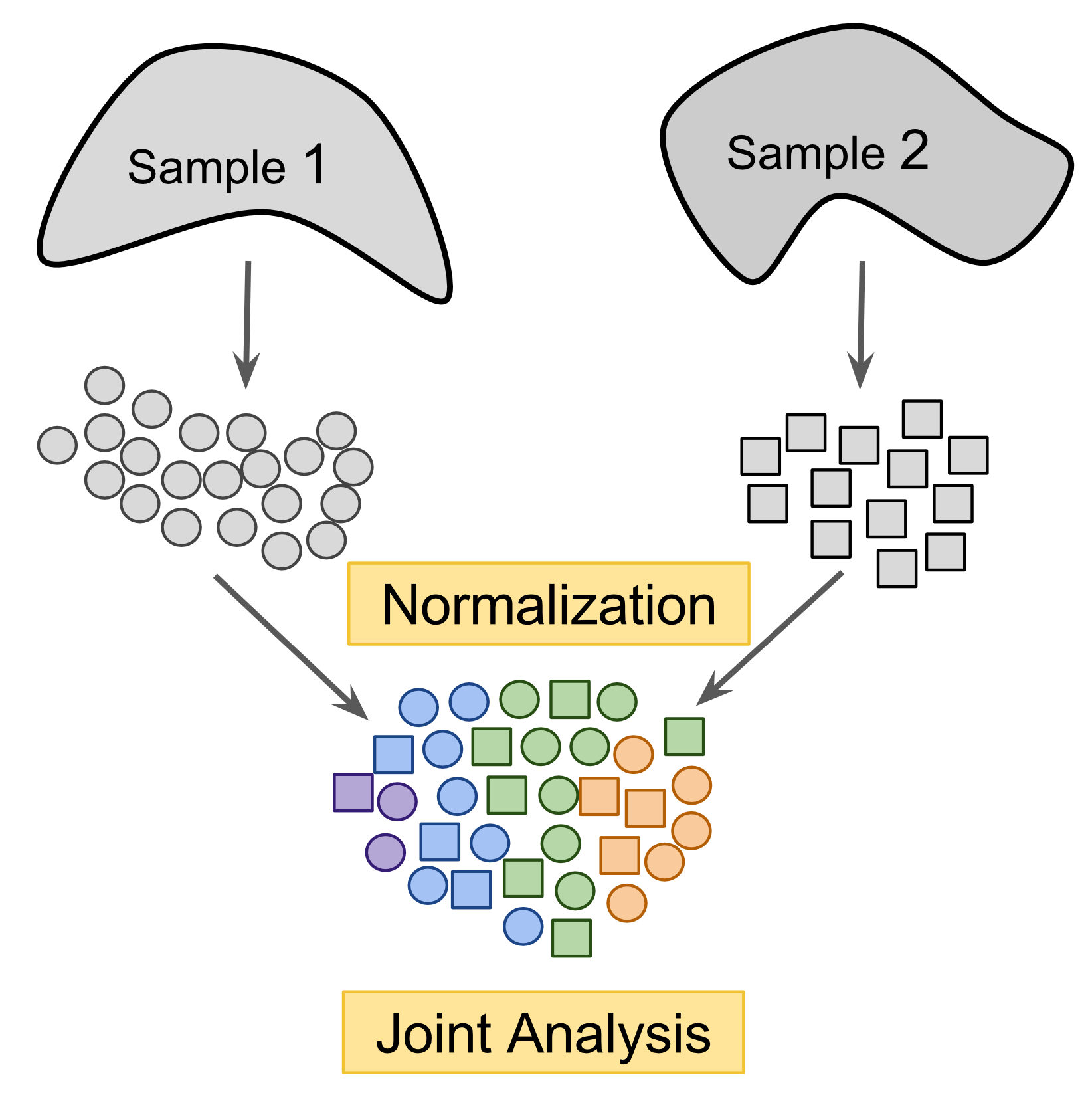
Figure 8.22: Cross-dataset normalization enables joint-analysis of 2+ scRNASeq datasets.
8.8.2 Datasets
在两个人胰腺数据集上运行这些方法:(Muraro et al. 2016)和(Segerstolpe et al. 2016)。 由于胰腺已被广泛研究,这些数据集得到了很好的注释。
此数据已针对scmap格式化。细胞类型label必须存储在colData的cell_type1列中,并且两个数据集之间一致的基因ID必须存储在rowData的feature_symbol列中。
首先,检查两个数据集中的gene-id匹配情况:
sum(rowData(muraro)$feature_symbol %in% rowData(segerstolpe)$feature_symbol)/nrow(muraro)
## [1] 0.9599519
sum(rowData(segerstolpe)$feature_symbol %in% rowData(muraro)$feature_symbol)/nrow(segerstolpe)
## [1] 0.719334muraro中6%基因与segerstople中的基因匹配,而segerstolpe中72%的基因与muraro匹配。因为segerstolpe数据集比muraro数据集测序深度更深。 然而,它突出了比较scRNA-Seq数据集的一些困难。
通过检查这两个数据集的总体大小来确认这一点。
此外,使用以下命令检查每个数据集的细胞类型注释:
summary(factor(colData(muraro)$cell_type1))
## acinar alpha beta delta ductal endothelial
## 219 812 448 193 245 21
## epsilon gamma mesenchymal unclear
## 3 101 80 4
summary(factor(colData(segerstolpe)$cell_type1))
## acinar alpha beta
## 185 886 270
## co-expression delta ductal
## 39 114 386
## endothelial epsilon gamma
## 16 7 197
## mast MHC class II not applicable
## 7 5 1305
## PSC unclassified unclassified endocrine
## 54 2 41即使两个数据集来自相同的生物组织,注释细胞类型也略有差异。如果您熟悉胰腺生物学,您可能会认识到segerstolpe中的pancreatic stellate cells (PSCs)是一种间充质干细胞,在muraro中属于"mesenchymal“类型。但是,目前尚不清楚这两个注释是否应该被视为同义词。 可以使用label-centric的比较方法来确定这两个细胞类型的注释是否确实相同。
或者,我们可以通过利用数据集中的形成来理解那些“unclassified endocrine”或被认为对每个数据集中的原始聚类质量太差(“not applicable”)的细胞的功能。 我们可以尝试使用label-centric的方法来推断它们最可能属于哪个现有注释,或者使用cross-dataset normalization来揭示其中的新颖细胞类型(或现有注释中的子类型)。
为了简化演示分析,我们将删除少量未分配类型的细胞和质量较差的细胞。但保留“unclassified endocrine”,看看这些方法中是否阐明它们属于哪种细胞类型。
8.8.3 scmap
scmap (Kiselev and Hemberg 2017),一种将scRNA-seq实验细胞投影到其他实验中鉴定的细胞类型上的方法。 此外,云版本的scmap可以免费运行,但有merged_seurat限制, http://www.hemberg-lab.cloud/scmap。
8.8.3.1 特征选择
创建SingleCellExperiment对象后可以直接运行scmap。首先构建参考cluster的“索引”。 由于我们想知道PSC和间充质细胞是否是同义词,需要将每个数据集投射到另一个,因此为每个数据集构建索引。 这需要首先为参考数据集选择信息量最大的特征。
## Warning in linearModel(object, n_features): Your object does not contain
## counts() slot. Dropouts were calculated using logcounts() slot...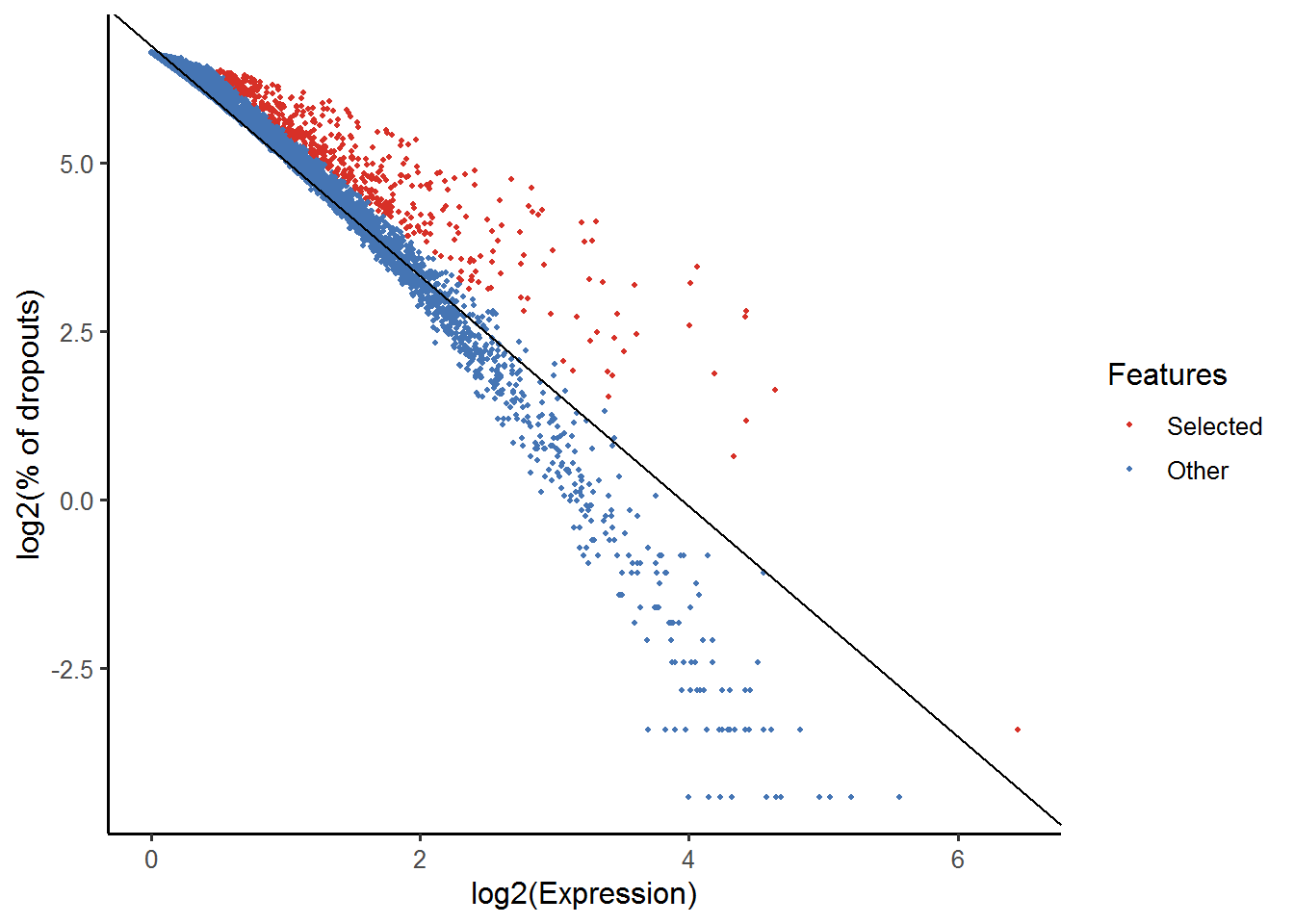
红色高亮的基因将用于进一步分析(投影)。
从这些图的y轴可以看出scmap使用基于dropmerged_seurat的特征选择方法。
计算细胞类型索引:
可视化索引:

如果特征过于集中在少数细胞类型中,可以使用setFeatures函数调整特征。
练习 使用每个数据集的rowData,两个数据集中有多少基因作为特征?
答案
8.8.3.2 投影
scmap计算从每个细胞到参考索引中每个细胞类型的距离,然后应用经验阈值来确定将哪些细胞分配给最近的参考细胞类型以及哪些细胞未分配。 为了解释测序深度的差异,使用spearman相关系数和余弦距离计算距离,并且仅当两种距离返回一致结果时,将结果分配给该细胞。
将segerstolpe投影到muraro数据集:
将muraro投影到segerstolpe
请注意,在每种情况下,我们都会投影到单个数据集,但这可以扩展到任意数量已计算索引的数据集。
比较原始细胞类型label与投影label:
table(colData(muraro)$cell_type1, muraro_to_seger$scmap_cluster_labs)
##
## acinar alpha beta co-expression delta ductal endothelial
## acinar 211 0 0 0 0 0 0
## alpha 1 763 0 18 0 2 0
## beta 2 1 397 7 2 2 0
## delta 0 0 2 1 173 0 0
## ductal 7 0 0 0 0 208 0
## endothelial 0 0 0 0 0 0 15
## epsilon 0 0 0 0 0 0 0
## gamma 2 0 0 0 0 0 0
## mesenchymal 0 0 0 0 0 1 0
##
## epsilon gamma MHC class II PSC unassigned
## acinar 0 0 0 0 8
## alpha 0 2 0 0 26
## beta 0 5 1 2 29
## delta 0 0 0 0 17
## ductal 0 0 5 3 22
## endothelial 0 0 0 1 5
## epsilon 3 0 0 0 0
## gamma 0 95 0 0 4
## mesenchymal 0 0 0 77 2在这里,我们可以看到细胞类型映射到segerstolpe,重要的是除了一个“间充质“细胞之外的所有细胞都被分配到“PSC”类。
table(colData(segerstolpe)$cell_type1, seger_to_muraro$scmap_cluster_labs)
##
## acinar alpha beta delta ductal endothelial
## acinar 181 0 0 0 4 0
## alpha 0 869 1 0 0 0
## beta 0 0 260 0 0 0
## co-expression 0 7 31 0 0 0
## delta 0 0 1 111 0 0
## ductal 0 0 0 0 383 0
## endothelial 0 0 0 0 0 14
## epsilon 0 0 0 0 0 0
## gamma 0 2 0 0 0 0
## mast 0 0 0 0 0 0
## MHC class II 0 0 0 0 0 0
## PSC 0 0 1 0 0 0
## unclassified endocrine 0 0 0 0 0 0
##
## epsilon gamma mesenchymal unassigned
## acinar 0 0 0 0
## alpha 0 0 0 16
## beta 0 0 0 10
## co-expression 0 0 0 1
## delta 0 0 0 2
## ductal 0 0 0 3
## endothelial 0 0 0 2
## epsilon 6 0 0 1
## gamma 0 192 0 3
## mast 0 0 0 7
## MHC class II 0 0 0 5
## PSC 0 0 53 0
## unclassified endocrine 0 0 0 41再次看到细胞类型相互匹配,除了“PSC”所有细胞除一个外都与“间充质”细胞相匹配,这提供了强有力的证据证明这两个注释应该被认为是同义词。
可以通过 桑葚图对上述表格进行可视化:
练习
之前未分类的细胞有多少可以使用scmap分配细胞类型?
答案
8.8.4 细胞间映射
scmap还可以将一个数据集中的每个细胞投影到参考数据集中的近似最近邻细胞。 这使用高度优化的搜索算法,允许它扩展到非常大的参考空间(理论上是100,000万个细胞)。 但是,这个过程是随机的,因此必须固定随机种子以确保可以重现结果。
我们已经为此数据集进行了特征选择,可以直接构建索引。
在这种情况下,索引是使用不同特征集的每个细胞的一系列聚类,参数k和M是聚类的数量和在这些子聚类中使用的特征的数量。 将新细胞分配给每个subcluster中最近的cluster,以生成唯一的聚类分配模式。 然后,在参考数据集中寻找具有相同或最相似的聚类分配模式的细胞。
检查参考数据集的聚类分配模式
metadata(muraro)$scmap_cell_index$subclusters[1:5,1:5]
## D28.1_1 D28.1_13 D28.1_15 D28.1_17 D28.1_2
## [1,] 4 6 4 24 34
## [2,] 16 27 14 11 3
## [3,] 18 12 17 26 24
## [4,] 44 33 41 44 12
## [5,] 39 44 23 34 32投影并寻找w最近邻:
muraro_to_seger <- scmapCell(
projection = muraro,
index_list = list(
seger = metadata(segerstolpe)$scmap_cell_index
),
w = 5
)查看结果:
muraro_to_seger$seger[[1]][,1:5]
## D28.1_1 D28.1_13 D28.1_15 D28.1_17 D28.1_2
## [1,] 1448 1381 1125 1834 1553
## [2,] 1731 855 1081 1731 1437
## [3,] 1229 2113 2104 1790 1890
## [4,] 2015 1833 1153 1882 1593
## [5,] 1159 1854 1731 1202 1078这显示了segerstolpe到muraro中的细胞5个最近邻居的列号。然后从segerstolpe数据的colData中选择适当的数据来计算伪时间估计,分支分配或其他细胞水平数据。作为演示,查找每个细胞的最近邻居的细胞类型。
8.8.5 Metaneighbour
Metaneighbour专门用于检查细胞类型是否在数据集之间保持一致。它有两个版本。 首先是一种完全监督的方法,它假设所有数据集中细胞类型一致,并计算这些细胞类型标记的“good”的程度。(下面将描述“good”的确切含义)。 或者,metaneighbour可以估计数据集内和数据集之间所有细胞类型彼此之间的相似程度。 我们将只使用无监督版本,因为它具有更广泛的适用性,并且更容易解释结果。
Metaneighbour通过构建细胞-细胞spearman相关网络来比较数据集中的细胞类型。然后通过最近邻居的加权投票来预测细胞类型。 然后将两个cluster之间的整体相似性评分为AUROC,基于加权投票将类型A的细胞分配给类型B. AUROC为1表示在任何其他细胞出现之前,所有类型A的细胞都被分配到类型B,如果细胞随机分配,则AUROC为0.5。
Metanighbour只是一些R函数而不是一个完整的R包,所以必须使用source加载它们
8.8.5.1 数据准备
Metaneighbour要求在运行之前将所有数据集组合成单个表达矩阵:
is.common <- rowData(muraro)$feature_symbol %in% rowData(segerstolpe)$feature_symbol
muraro <- muraro[is.common,]
segerstolpe <- segerstolpe[match(rowData(muraro)$feature_symbol, rowData(segerstolpe)$feature_symbol),]
rownames(segerstolpe) <- rowData(segerstolpe)$feature_symbol
rownames(muraro) <- rowData(muraro)$feature_symbol
identical(rownames(segerstolpe), rownames(muraro))
combined_logcounts <- cbind(logcounts(muraro), logcounts(segerstolpe))
dataset_labels <- rep(c("m", "s"), times=c(ncol(muraro), ncol(segerstolpe)))
cell_type_labels <- c(colData(muraro)$cell_type1, colData(segerstolpe)$cell_type1)
pheno <- data.frame(Sample_ID = colnames(combined_logcounts),
Study_ID=dataset_labels,
Celltype=paste(cell_type_labels, dataset_labels, sep="-"))
rownames(pheno) <- colnames(combined_logcounts)Metaneighbor包括识别HVG的特征选择方法。
由于Metaneighbor比scmap慢得多,对这些数据集进行下采样。
subset <- sample(1:nrow(pheno), 2000)
combined_logcounts <- combined_logcounts[,subset]
pheno <- pheno[subset,]
cell_type_labels <- cell_type_labels[subset]
dataset_labels <- dataset_labels[subset]现在准备运行Metaneighbor。首先,运行无监督版本,查看两个数据集中哪些细胞类型最相似。
unsup <- run_MetaNeighbor_US(var.genes, combined_logcounts, unique(pheno$Celltype), pheno)
heatmap(unsup)
8.8.6 mnnCorrect
mnnCorrect校正数据集以促进联合分析。 为了解释两个重复或两个不同实验之间的组成差异,首先匹配实验中的单个细胞以找到重叠的生物结构。 使用该重叠结构学习表达的哪个维度对应于生物状态以及哪个维度对应于批次/实验效应; mnnCorrect假设这些维度在高维表达空间中是彼此正交的。 最后,从整个表达矩阵中删除批次/实验效应,返回校正后的矩阵。
为了跨数据集匹配细胞,mnnCorrect使用余弦距离来避免文库大小效应,跨数据集识别mututal nearest neighbours(k确定邻居大小)。 只有重叠的生物群应该有mutual nearest neighbours(见下图b)。 然而,这假设k被设置为数据集中最小生物群的大小,但是k越小将识别太少的mutual nearest-neighbour对来对批次效应进行良好估计。
学习生物/技术效应的方法是使用奇异值分解,类似于批次校正部分中的RUV,或者使用优化的irlba包进行主成分分析,这比SVD快。 参数svd.dim指定应该保留多少维度来总结数据的生物结构,我们将它设置为三,因为使用上面的Metaneighbor发现有三个主要组。 可以通过平滑(sigma)和/或方差调整(var.adj)进一步调整这些估计。
mnnCorrect还假设您已经对表达式矩阵去子集,以便相同的基因具有相同的顺。当为Metaneighbor设置数据时,我们已经为数据集做了这些。
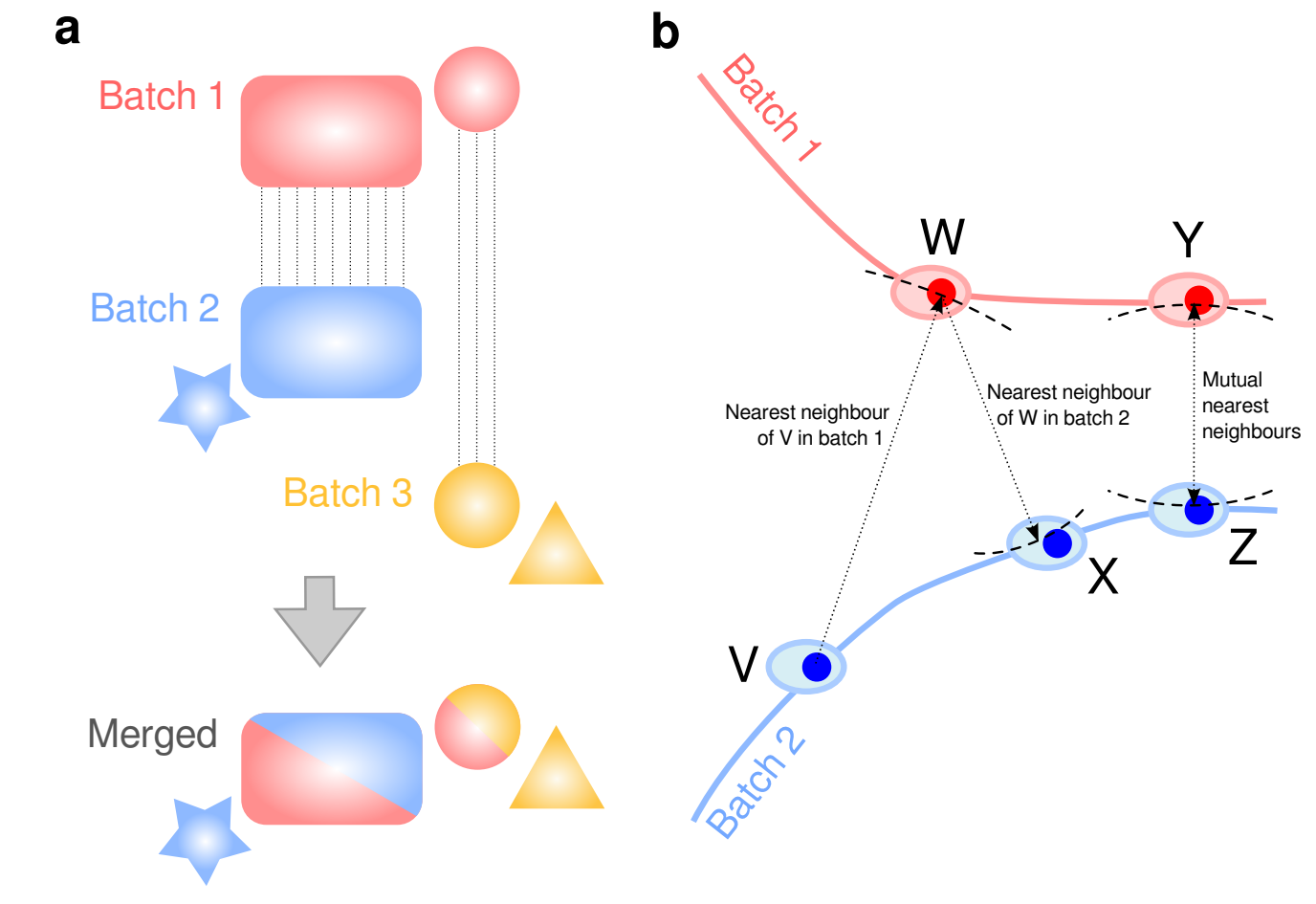
Figure 8.23: mnnCorrect batch/dataset effect correction. From Haghverdi et al. 2017
require("scran")
# mnnCorrect will take several minutes to run
corrected <- mnnCorrect(logcounts(muraro), logcounts(segerstolpe), k=20, sigma=1, pc.approx=TRUE, subset.row=var.genes, svd.dim=3)首先让我们检查一下是否找到了足够数量的mnn对,mnnCorrect返回一个数据框列表,其中包含每个数据集的mnn对。
dim(corrected$pairs[[1]]) # muraro -> others
## [1] 0 3
dim(corrected$pairs[[2]]) # seger -> others
## [1] 2533 3第一列和第二列包含细胞列ID,第三列数字代表第二列细胞属于哪个数据集/批次。在我们的例子中只比较两个数据集,因此所有mnn对都已分配给第二个表,第三个列只包含一个。
head(corrected$pairs[[2]])
## DataFrame with 6 rows and 3 columns
## current.cell other.cell other.batch
## <integer> <Rle> <Rle>
## 1 1553 5 1
## 2 1078 5 1
## 3 1437 5 1
## 4 1890 5 1
## 5 1569 5 1
## 6 373 5 1
total_pairs <- nrow(corrected$pairs[[2]])
n_unique_seger <- length(unique((corrected$pairs[[2]][,1])))
n_unique_muraro <- length(unique((corrected$pairs[[2]][,2])))mnnCorrect在n_unique_seger segerstolpe cell和n_unique_muraro muraro cells之间找到了2533组mutual nearest-neighbours。 这应该是足够数量的对,但每个数据集中的独特细胞数量较少表明可能没有捕获每个数据集中的完整生物信号。
练习 哪些细胞类型在这些数据集中有mnns?应该增加/减少k吗?
答案
seger_matched_cells <- unique((corrected$pairs[[2]][,1]))
summary(factor(colData(segerstolpe)$cell_type1[seger_matched_cells]))
muraro_matched_cells <- unique((corrected$pairs[[2]][,2]))
summary(factor(colData(muraro)$cell_type1[muraro_matched_cells]))现在创建一个组合数据集来联合分析这些数据。但是,校正的数据不再是counts,通常包含负值,因此某些分析工具可能不再适用。 简单起见,绘制一个联合TSNE。
require("Rtsne")
joint_expression_matrix <- cbind(corrected$corrected[[1]], corrected$corrected[[2]])
# Tsne will take some time to run on the full dataset
joint_tsne <- Rtsne(t(joint_expression_matrix[rownames(joint_expression_matrix) %in% var.genes,]), initial_dims=10, theta=0.75,
check_duplicates=FALSE, max_iter=200, stop_lying_iter=50, mom_switch_iter=50)
dataset_labels <- factor(rep(c("m", "s"), times=c(ncol(muraro), ncol(segerstolpe))))
cell_type_labels <- factor(c(colData(muraro)$cell_type1, colData(segerstolpe)$cell_type1))
plot(joint_tsne$Y[,1], joint_tsne$Y[,2], pch=c(16,1)[dataset_labels], col=rainbow(length(levels(cell_type_labels)))[cell_type_labels])
8.8.7 典型相关分析 (Seurat)
Seurat包中包含另一种用于组合多个数据集的校正方法,称为 CCA。 但是,与mnnCorrect不同,它不直接校正表达矩阵本身。相反,Seurat为每个数据集找到一个较低维度的子空间,然后校正这些子空间。 与mnnCorrect不同,Seurat一次只组合一对数据集。
Seurat通过称为典型相关分析(CCA)的方法使用基因-基因相关性识别数据集中的生物结构。Seurat学习基因-基因相关性的共享结构,然后评估每个细胞与这种结构的拟合程度。必须通过数据特异的降维方法而不是共享相关结构描述的细胞代表数据集特异的细胞类型/状态,在比对两个数据集前舍去。 最后,使用’warping’算法比对两个数据集,该算法对每个数据集的低维表示进行归一化,其对群体密度差异稳健。
注意,因为Seurat占用了大量的库空间,必须重新启动R-session才能加载它,并且不会在此页面上自动生成plots / merged_seuratput。
重新加载数据:
首先,将数据重新格式化为Seurat对象:
对每个数据集进行标准化,缩放和识别HGV:
Figure 8.24: muraro variable genes
Figure 8.25: segerstolpe variable genes
尽管Seurat校正了离散程度和表达均值之间的关系,对特征进行排名时也不使用校正值。将以下命令的结果与上图中的结果进行比较:
按照他们的例子使用前2000个最分散的基因并用merged_seurat来校正每个数据集的表达均值。
gene.use <- union(rownames(x = head(x = muraro_seurat@hvg.info, n = 2000)),
rownames(x = head(x = seger_seurat@hvg.info, n = 2000)))练习 如果选择按均值缩放后top2000的特征,这些特征是什么? 答案
seger_hvg <- seger_seurat@hvg.info
seger_hvg <- seger_hvg[order(seger_hvg[,3], decreasing=TRUE),]
muraro_hvg <- seger_seurat@hvg.info
muraro_hvg <- muraro_hvg[order(muraro_hvg[,3], decreasing=TRUE),]
gene.use.scaled <- union(rownames(seger_hvg[1:2000,]), rownames(muraro_hvg[1:2000,]))运行CCA来查找这两个数据集的共享相关结构:
请注意,为了加快计算速度,我们将仅使用前5个维度,但理想情况下,您会考虑更多,然后使用DimHeatmap选择信息最丰富的维度。
merged_seurat <- RunCCA(object=muraro_seurat, object2=seger_seurat, genes.use=gene.use, add.cell.id1="m", add.cell.id2="s", num.cc = 5)
DimPlot(object = merged_seurat, reduction.use = "cca", group.by = "dataset", pt.size = 0.5) # Before correcting
Figure 8.26: Before Aligning
为了识别特定于数据集的细胞类型,我们比较了CCA与特定数据集主成分分析“解释”细胞的程度。
merged_seurat <- CalcVarExpRatio(object = merged_seurat, reduction.type = "pca", grouping.var = "dataset", dims.use = 1:5)
merged.all <- merged_seurat
merged_seurat <- SubsetData(object=merged_seurat, subset.name="var.ratio.pca", accept.low = 0.5) # CCA > 1/2 as good as PCA
merged.discard <- SubsetData(object=merged.all, subset.name="var.ratio.pca", accept.high = 0.5)
summary(factor(merged.discard@meta.data$celltype)) # check the cell-type of the discarded cells.在这里我们可以看到,尽管两个数据集都包含内皮细胞,但几乎都作为“dataset-specific”被丢弃。下面比对数据集:
merged_seurat <- AlignSubspace(object = merged_seurat, reduction.type = "cca", grouping.var = "dataset", dims.align = 1:5)
DimPlot(object = merged_seurat, reduction.use = "cca.aligned", group.by = "dataset", pt.size = 0.5) # After aligning subspaces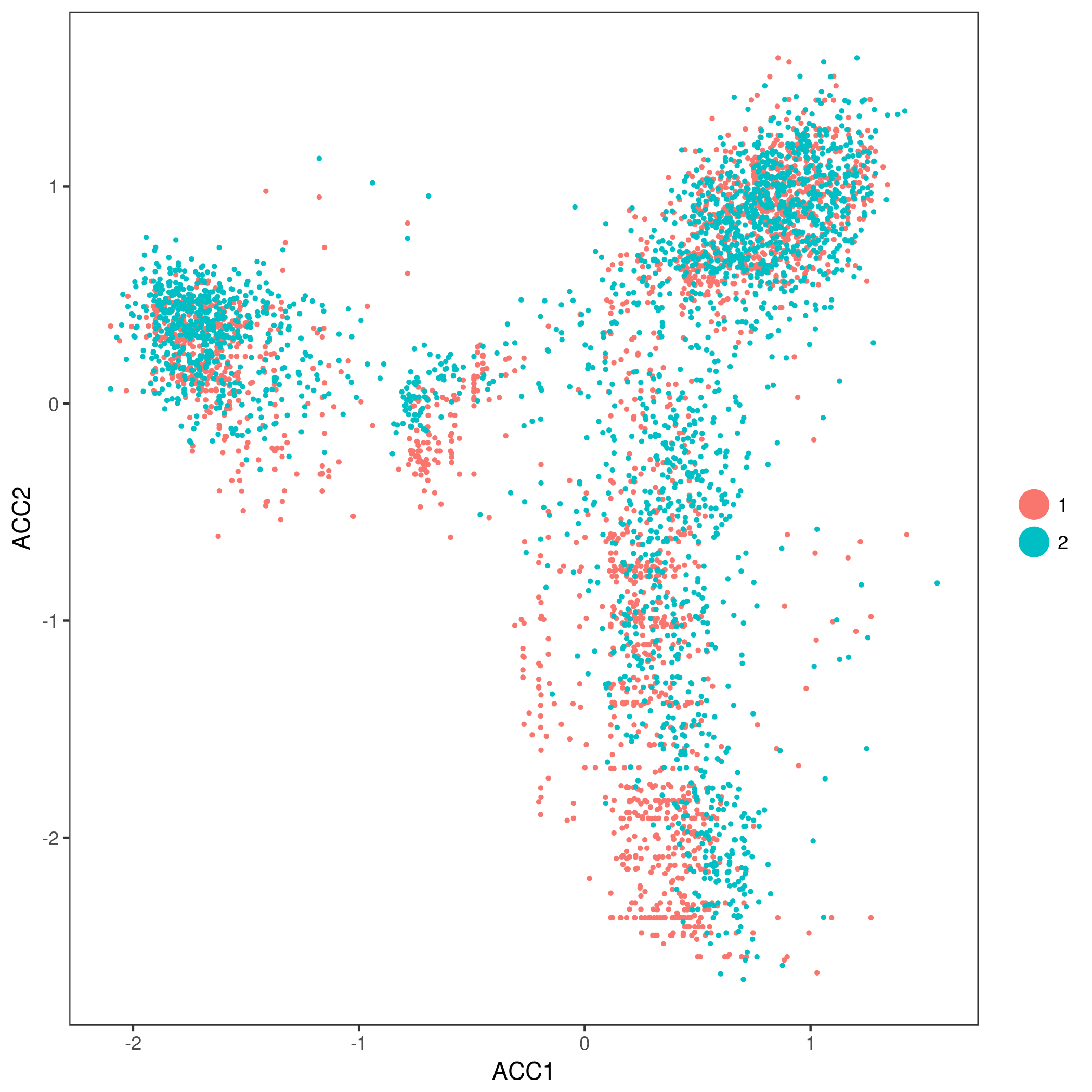
Figure 8.27: After Aligning
练习 比较使用离散程度缩放的特征结果
答案
merged_seurat <- RunCCA(object=muraro_seurat, object2=seger_seurat, genes.use=gene.use.scaled, add.cell.id1="m", add.cell.id2="s", num.cc = 5)
merged_seurat <- AlignSubspace(object = merged_seurat, reduction.type = "cca", grouping.var = "dataset", dims.align = 1:5)
DimPlot(object = merged_seurat, reduction.use = "cca.aligned", group.by = "dataset", pt.size = 0.5) # After aligning subspaces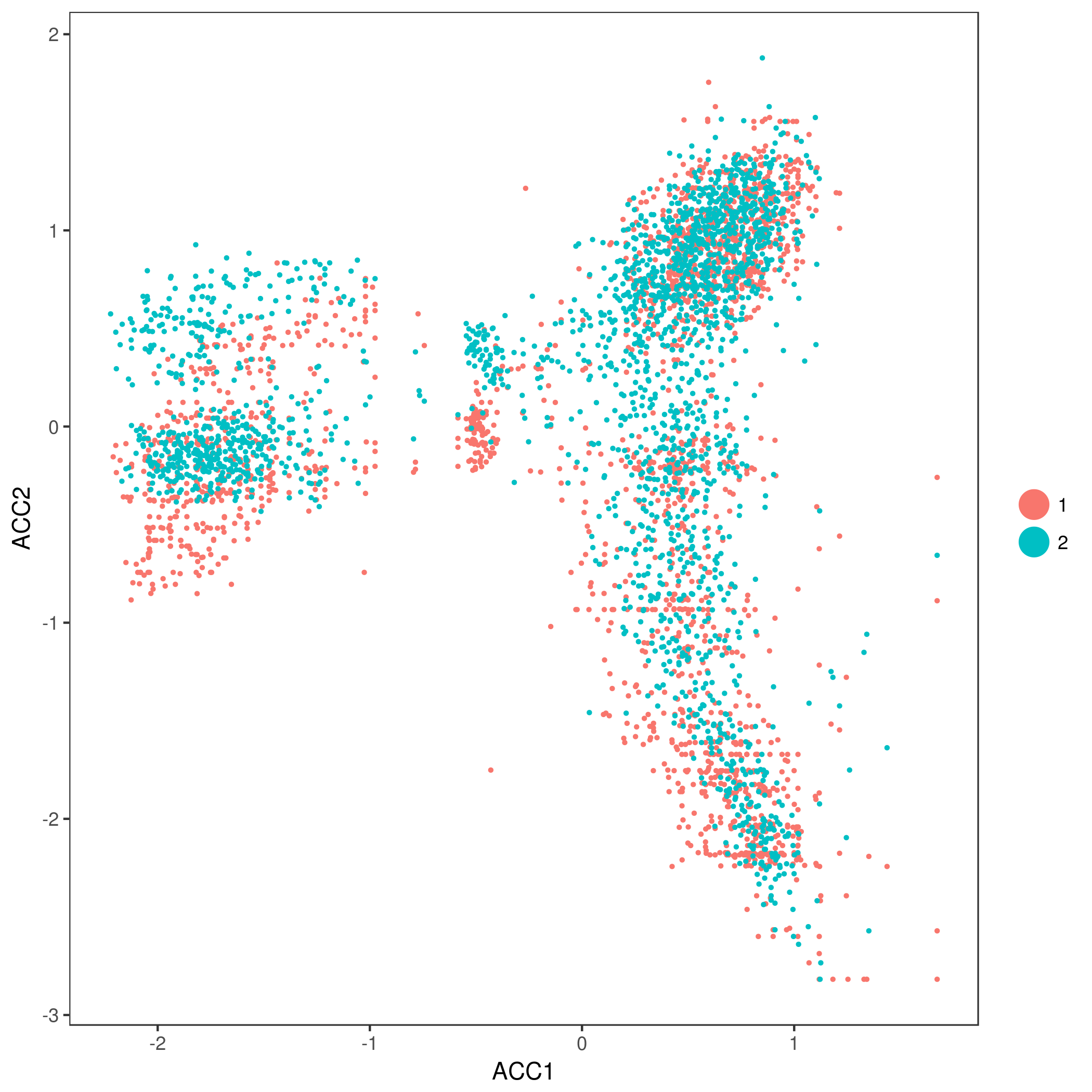
Figure 8.28: After Aligning
进阶练习 使用我们之前在组合数据集上介绍的聚类方法。是否发现任何新型细胞类型?
8.9 检索scRNA-seq数据
8.9.1 About
scfind是可以使用基因列表搜索单细胞RNA-Seq集合(Atlas)的工具,寻找表达特定基因集表达的细胞和细胞类型。scfind是一个Github包。 网站提供了包含大量数据集的scfind云版本。
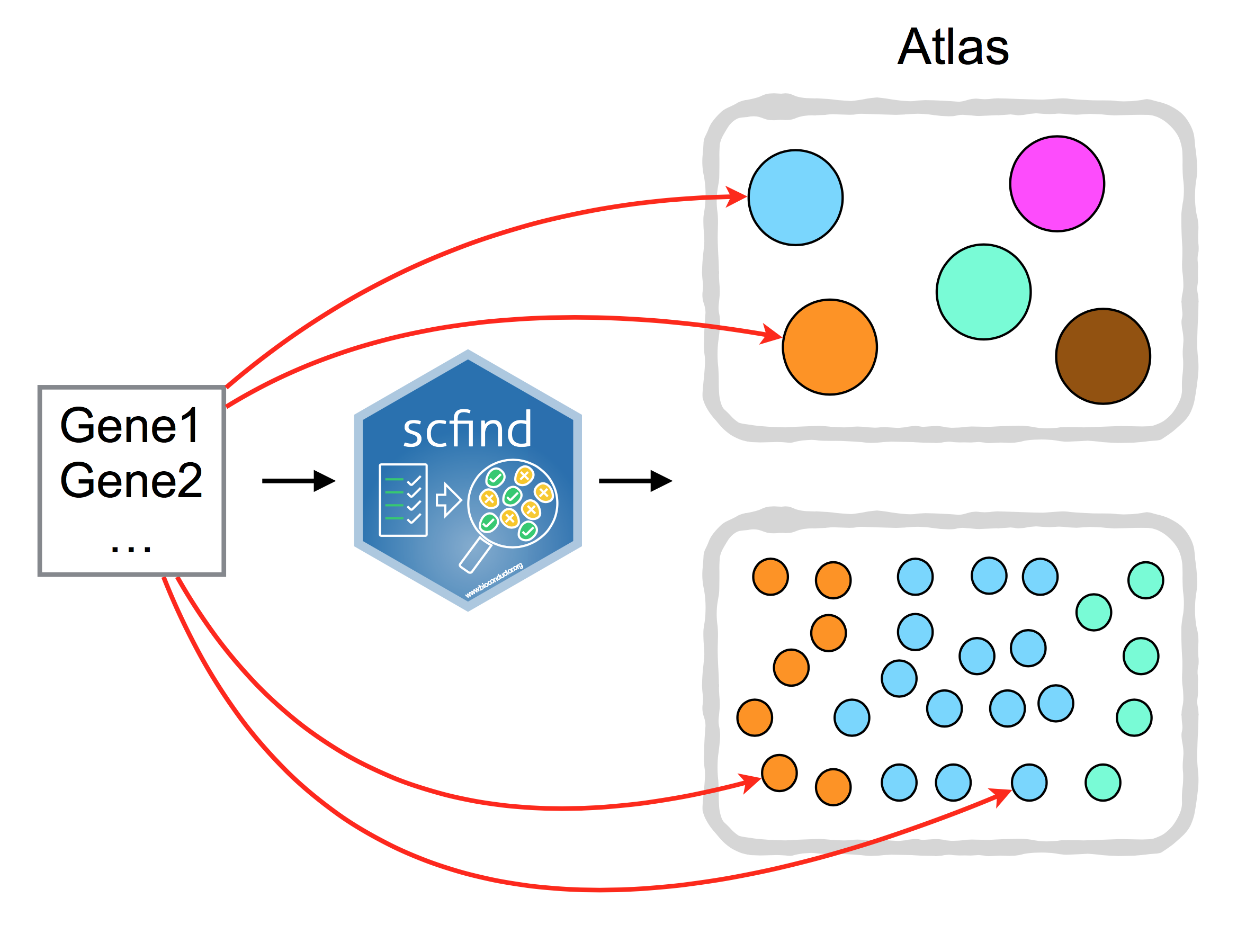
Figure 8.29: scfind can be used to search large collection of scRNA-seq data by a list of gene IDs.
8.9.2 数据集
在Tabula Muris 10X数据集上运行scfind。scfind还在SingleCellExperiment类上运行:
## class: SingleCellExperiment
## dim: 23341 654
## metadata(1): log.exprs.offset
## assays(3): counts normcounts logcounts
## rownames(23341): Xkr4 Rp1 ... Tdtom_transgene zsGreen_transgene
## rowData names(1): feature_symbol
## colnames(654): 10X_P7_4_AAACCTGCACGACGAA-1
## 10X_P7_4_AAACCTGGTTCCACGG-1 ... 10X_P7_4_TTTGTCAGTCGATTGT-1
## 10X_P7_4_TTTGTCAGTGCGCTTG-1
## colData names(5): mouse cell_type1 tissue subtissue sex
## reducedDimNames(3): UMAP PCA TSNE
## spikeNames(0):## DataFrame with 654 rows and 5 columns
## mouse cell_type1 tissue
## <factor> <factor> <factor>
## 10X_P7_4_AAACCTGCACGACGAA-1 3-F-56 endothelial cell Heart
## 10X_P7_4_AAACCTGGTTCCACGG-1 3-F-56 fibroblast Heart
## 10X_P7_4_AAACCTGTCTCGATGA-1 3-F-56 endothelial cell Heart
## 10X_P7_4_AAACGGGAGCGCTCCA-1 3-F-56 cardiac muscle cell Heart
## 10X_P7_4_AAAGCAAAGTGAATTG-1 3-F-56 fibroblast Heart
## ... ... ... ...
## 10X_P7_4_TTTGGTTCAGACTCGC-1 3-F-56 cardiac muscle cell Heart
## 10X_P7_4_TTTGTCAAGTGGAGAA-1 3-F-56 cardiac muscle cell Heart
## 10X_P7_4_TTTGTCACAAGCCATT-1 3-F-56 endocardial cell Heart
## 10X_P7_4_TTTGTCAGTCGATTGT-1 3-F-56 endothelial cell Heart
## 10X_P7_4_TTTGTCAGTGCGCTTG-1 3-F-56 fibroblast Heart
## subtissue sex
## <factor> <factor>
## 10X_P7_4_AAACCTGCACGACGAA-1 NA F
## 10X_P7_4_AAACCTGGTTCCACGG-1 NA F
## 10X_P7_4_AAACCTGTCTCGATGA-1 NA F
## 10X_P7_4_AAACGGGAGCGCTCCA-1 NA F
## 10X_P7_4_AAAGCAAAGTGAATTG-1 NA F
## ... ... ...
## 10X_P7_4_TTTGGTTCAGACTCGC-1 NA F
## 10X_P7_4_TTTGTCAAGTGGAGAA-1 NA F
## 10X_P7_4_TTTGTCACAAGCCATT-1 NA F
## 10X_P7_4_TTTGTCAGTCGATTGT-1 NA F
## 10X_P7_4_TTTGTCAGTGCGCTTG-1 NA F8.9.3 基因索引
使用数据集创建基因索引:
heart_index <- buildCellTypeIndex(
sce = tm10x_heart,
assay.name = "counts",
cell.type.label = "cell_type1",
dataset.name = "Heart"
)## Generating index for Heart from ' counts ' assay## Indexing cardiac muscle cell as Heart.cardiac muscle cell with 83 cells.## Indexing endocardial cell as Heart.endocardial cell with 65 cells.## Indexing endothelial cell as Heart.endothelial cell with 178 cells.## Indexing erythrocyte as Heart.erythrocyte with 55 cells.## Indexing fibroblast as Heart.fibroblast with 222 cells.## Indexing smooth muscle cell as Heart.smooth muscle cell with 21 cells.scfind采用两步压缩策略,有效压缩大型cell-by-gene矩阵,并允许通过基因查询快速检索数据。估计用这种方法可以达到2个数量级的压缩。
索引的输入矩阵是SingleCellExperiment类的原始count矩阵。 默认情况下,SingleCellExperiment对象的colData的cell_type1列用于定义细胞类型,但也可以使用buildCellTypeIndex的cell.type.label参数手动定义。对于具有多个组织的数据集,还可以使用函数mergeDataset将所有组织合并在一起以创建超级索引。
索引可以使用saveObject函数以.rds格式保存,并使用loadObject函数加载以备将来使用。
tm10x_thymus <- readRDS("data/sce/Thymus_10X.rds")
thymus_index <- buildCellTypeIndex(
sce = tm10x_thymus,
assay.name = "counts",
cell.type.label = "cell_type1",
dataset.name = "Thymus"
)## Generating index for Thymus from ' counts ' assay## Indexing stromal cell as Thymus.stromal cell with 112 cells.## Indexing T cell as Thymus.T cell with 1317 cells.## Merging Thymus## [1] "Heart" "Thymus"## [1] "Heart.cardiac muscle cell" "Heart.endocardial cell"
## [3] "Heart.endothelial cell" "Heart.erythrocyte"
## [5] "Heart.fibroblast" "Heart.smooth muscle cell"
## [7] "Thymus.stromal cell" "Thymus.T cell"## [1] "Cwc15" "Ttc33" "Plbd2" "Arhgap12"
## [5] "AA465934" "Ulk3" "Foxa3" "Htra3"
## [9] "Gpr84" "Lcn8" "Zfp498" "Basp1"
## [13] "A430105I19Rik" "Dhrs2" "Zmym3" "Rara"
## [17] "Lrrc24" "Rps8" "Ttc14" "Igsf5"使用交互式Shiny快速找到细胞类型,使用如下命令: To quickly and easily find the enriched cell type using an interactive Shiny application use the following method:
8.9.4 Marker基因
在数据集中找到Thymus T细胞的标记基因
# Showing the top 5 marker genes for each cell type and sort by F1 score.
t_cell_markers <- cellTypeMarkers(scfind_index, cell.types = "Thymus.T cell", top.k = 5, sort.field = "f1") ## Considering the whole DB..## cellType genes tp fp fn precision recall f1
## 2628 Thymus.T cell Cd3d 1311 108 6 0.9238901 0.9954442 0.9583333
## 6616 Thymus.T cell Lck 1305 106 12 0.9248759 0.9908884 0.9567448
## 2631 Thymus.T cell Cd3g 1304 108 13 0.9235128 0.9901291 0.9556614
## 2629 Thymus.T cell Cd3e 1279 98 38 0.9288308 0.9711465 0.9495174
## 6603 Thymus.T cell Lat 1280 109 37 0.9215263 0.9719059 0.9460459评估Thymus stromal细胞中Thymus T cell的marker
evaluateMarkers(
scfind_index,
gene.list = as.character(t_cell_markers$genes),
cell.types = "Thymus.stromal cell",
sort.field = "f1"
)## Considering the whole DB..## cellType genes tp fp fn precision recall f1
## 2 Thymus.stromal cell Cd3e 90 1287 22 0.06535947 0.8035714 0.1208865
## 3 Thymus.stromal cell Cd3g 94 1318 18 0.06657224 0.8392857 0.1233596
## 5 Thymus.stromal cell Lck 94 1317 18 0.06661942 0.8392857 0.1234406
## 1 Thymus.stromal cell Cd3d 98 1321 14 0.06906272 0.8749999 0.1280209
## 4 Thymus.stromal cell Lat 99 1290 13 0.07127430 0.8839286 0.1319121# By default, the marker evaluation takes all cell types in the dataset as background cell type, but you can use the argument `background.cell.types` to fine tune the evaluation
background <- cellTypeNames(scfind_index, datasets = "Thymus")
background## [1] "Thymus.stromal cell" "Thymus.T cell"evaluateMarkers(
scfind_index,
gene.list = as.character(t_cell_markers$genes),
cell.types = "Thymus.stromal cell",
sort.field = "f1",
background.cell.types = background
)## cellType genes tp fp fn precision recall f1
## 2 Thymus.stromal cell Cd3e 90 1279 22 0.06574142 0.8035714 0.1215395
## 5 Thymus.stromal cell Lck 94 1305 18 0.06719085 0.8392857 0.1244209
## 3 Thymus.stromal cell Cd3g 94 1304 18 0.06723891 0.8392857 0.1245033
## 1 Thymus.stromal cell Cd3d 98 1311 14 0.06955288 0.8749999 0.1288626
## 4 Thymus.stromal cell Lat 99 1280 13 0.07179116 0.8839286 0.13279688.9.5 搜索基因列表
scfind可以快速从大型单细胞数据集中识别出最能代表感兴趣基因的细胞类型。我们使用文献 Yanbin et al. 2015鉴定的标记基因。
用于免疫染色的心肌细胞特异性标志物如图1所示。
cardiomyocytes <- c("Mef2c", "Gata4", "Nkx2.5", "Myh6", "tnnt2", "tnni3", "CDH2", "Cx43", "GJA1")
result <- markerGenes(
scfind_index,
gene.list = cardiomyocytes
)## Ignored Nkx2.5, Cx43. Not found in the index## calculating tfidf for the reduced expression matrix...## Genes Query tfidf Cells
## 1 2 Cdh2,Gata4 1.075548 27
## 2 3 Cdh2,Gata4,Gja1 2.085320 18
## 3 4 Cdh2,Gata4,Gja1,Mef2c 2.812912 11
## 4 5 Cdh2,Gata4,Gja1,Mef2c,Myh6 9.754036 8
## 5 6 Cdh2,Gata4,Gja1,Mef2c,Myh6,Tnni3 13.983566 8
## 6 7 Cdh2,Gata4,Gja1,Mef2c,Myh6,Tnni3,Tnnt2 18.241363 8
## 7 6 Cdh2,Gata4,Gja1,Mef2c,Myh6,Tnnt2 14.011833 8
## 8 5 Cdh2,Gata4,Gja1,Mef2c,Tnni3 7.042442 8
## 9 6 Cdh2,Gata4,Gja1,Mef2c,Tnni3,Tnnt2 11.300239 8
## 10 5 Cdh2,Gata4,Gja1,Mef2c,Tnnt2 7.070709 8
## 11 4 Cdh2,Gata4,Gja1,Myh6 9.026444 14
## 12 5 Cdh2,Gata4,Gja1,Myh6,Tnni3 13.255974 14
## 13 6 Cdh2,Gata4,Gja1,Myh6,Tnni3,Tnnt2 17.513771 14
## 14 5 Cdh2,Gata4,Gja1,Myh6,Tnnt2 13.284241 14
## 15 4 Cdh2,Gata4,Gja1,Tnni3 6.314850 14
## 16 5 Cdh2,Gata4,Gja1,Tnni3,Tnnt2 10.572647 14
## 17 4 Cdh2,Gata4,Gja1,Tnnt2 6.343117 15
## 18 3 Cdh2,Gata4,Mef2c 1.803140 14
## 19 4 Cdh2,Gata4,Mef2c,Myh6 8.744264 8
## 20 5 Cdh2,Gata4,Mef2c,Myh6,Tnni3 12.973794 8
## 21 6 Cdh2,Gata4,Mef2c,Myh6,Tnni3,Tnnt2 17.231591 8
## 22 5 Cdh2,Gata4,Mef2c,Myh6,Tnnt2 13.002062 8
## 23 4 Cdh2,Gata4,Mef2c,Tnni3 6.032670 9
## 24 5 Cdh2,Gata4,Mef2c,Tnni3,Tnnt2 10.290467 8
## 25 4 Cdh2,Gata4,Mef2c,Tnnt2 6.060938 8
## 26 3 Cdh2,Gata4,Myh6 8.016672 15
## 27 4 Cdh2,Gata4,Myh6,Tnni3 12.246202 14
## 28 5 Cdh2,Gata4,Myh6,Tnni3,Tnnt2 16.503999 14
## 29 4 Cdh2,Gata4,Myh6,Tnnt2 12.274470 14
## 30 3 Cdh2,Gata4,Tnni3 5.305078 17
## 31 4 Cdh2,Gata4,Tnni3,Tnnt2 9.562876 15
## 32 3 Cdh2,Gata4,Tnnt2 5.333346 17
## 33 2 Cdh2,Gja1 1.864063 39
## 34 3 Cdh2,Gja1,Mef2c 2.716969 18
## 35 4 Cdh2,Gja1,Mef2c,Myh6 10.853567 15
## 36 5 Cdh2,Gja1,Mef2c,Myh6,Tnni3 15.811551 15
## 37 6 Cdh2,Gja1,Mef2c,Myh6,Tnni3,Tnnt2 20.802671 15
## 38 5 Cdh2,Gja1,Mef2c,Myh6,Tnnt2 15.844687 15
## 39 4 Cdh2,Gja1,Mef2c,Tnni3 7.674953 15
## 40 5 Cdh2,Gja1,Mef2c,Tnni3,Tnnt2 12.666073 15
## 41 4 Cdh2,Gja1,Mef2c,Tnnt2 7.708089 15
## 42 3 Cdh2,Gja1,Myh6 10.000661 32
## 43 4 Cdh2,Gja1,Myh6,Tnni3 14.958645 32
## 44 5 Cdh2,Gja1,Myh6,Tnni3,Tnnt2 19.949766 32
## 45 4 Cdh2,Gja1,Myh6,Tnnt2 14.991781 32
## 46 3 Cdh2,Gja1,Tnni3 6.822047 33
## 47 4 Cdh2,Gja1,Tnni3,Tnnt2 11.813168 33
## 48 3 Cdh2,Gja1,Tnnt2 6.855183 34
## 49 2 Cdh2,Mef2c 1.533283 27
## 50 3 Cdh2,Mef2c,Myh6 9.669881 17
## 51 4 Cdh2,Mef2c,Myh6,Tnni3 14.627866 15
## 52 5 Cdh2,Mef2c,Myh6,Tnni3,Tnnt2 19.618986 15
## 53 4 Cdh2,Mef2c,Myh6,Tnnt2 14.661002 16
## 54 3 Cdh2,Mef2c,Tnni3 6.491268 18
## 55 4 Cdh2,Mef2c,Tnni3,Tnnt2 11.482388 16
## 56 3 Cdh2,Mef2c,Tnnt2 6.524404 18
## 57 2 Cdh2,Myh6 8.816976 36
## 58 3 Cdh2,Myh6,Tnni3 13.774960 32
## 59 4 Cdh2,Myh6,Tnni3,Tnnt2 18.766080 32
## 60 3 Cdh2,Myh6,Tnnt2 13.808096 33
## 61 2 Cdh2,Tnni3 5.638362 38
## 62 3 Cdh2,Tnni3,Tnnt2 10.629482 35
## 63 2 Cdh2,Tnnt2 5.671498 43
## 64 2 Gata4,Gja1 1.504907 41
## 65 3 Gata4,Gja1,Mef2c 2.232499 19
## 66 4 Gata4,Gja1,Mef2c,Myh6 9.173623 9
## 67 5 Gata4,Gja1,Mef2c,Myh6,Tnni3 13.403153 8
## 68 6 Gata4,Gja1,Mef2c,Myh6,Tnni3,Tnnt2 17.660950 8
## 69 5 Gata4,Gja1,Mef2c,Myh6,Tnnt2 13.431420 8
## 70 4 Gata4,Gja1,Mef2c,Tnni3 6.462029 11
## 71 5 Gata4,Gja1,Mef2c,Tnni3,Tnnt2 10.719826 10
## 72 4 Gata4,Gja1,Mef2c,Tnnt2 6.490296 11
## 73 3 Gata4,Gja1,Myh6 8.446031 22
## 74 4 Gata4,Gja1,Myh6,Tnni3 12.675561 19
## 75 5 Gata4,Gja1,Myh6,Tnni3,Tnnt2 16.933358 19
## 76 4 Gata4,Gja1,Myh6,Tnnt2 12.703828 19
## 77 3 Gata4,Gja1,Tnni3 5.734437 22
## 78 4 Gata4,Gja1,Tnni3,Tnnt2 9.992234 21
## 79 3 Gata4,Gja1,Tnnt2 5.762704 26
## 80 2 Gata4,Mef2c 1.222727 65
## 81 3 Gata4,Mef2c,Myh6 8.163851 20
## 82 4 Gata4,Mef2c,Myh6,Tnni3 12.393381 13
## 83 5 Gata4,Mef2c,Myh6,Tnni3,Tnnt2 16.651178 9
## 84 4 Gata4,Mef2c,Myh6,Tnnt2 12.421649 10
## 85 3 Gata4,Mef2c,Tnni3 5.452257 25
## 86 4 Gata4,Mef2c,Tnni3,Tnnt2 9.710054 14
## 87 3 Gata4,Mef2c,Tnnt2 5.480525 21
## 88 2 Gata4,Myh6 7.436259 46
## 89 3 Gata4,Myh6,Tnni3 11.665789 30
## 90 4 Gata4,Myh6,Tnni3,Tnnt2 15.923586 24
## 91 3 Gata4,Myh6,Tnnt2 11.694057 25
## 92 2 Gata4,Tnni3 4.724665 57
## 93 3 Gata4,Tnni3,Tnnt2 8.982463 34
## 94 2 Gata4,Tnnt2 4.752933 61
## 95 2 Gja1,Mef2c 2.553022 91
## 96 3 Gja1,Mef2c,Myh6 12.752868 35
## 97 4 Gja1,Mef2c,Myh6,Tnni3 18.968080 31
## 98 5 Gja1,Mef2c,Myh6,Tnni3,Tnnt2 25.224830 26
## 99 4 Gja1,Mef2c,Myh6,Tnnt2 19.009619 27
## 100 3 Gja1,Mef2c,Tnni3 8.768234 43
## 101 4 Gja1,Mef2c,Tnni3,Tnnt2 15.024984 34
## 102 3 Gja1,Mef2c,Tnnt2 8.809772 44
## 103 2 Gja1,Myh6 16.214932 71
## 104 3 Gja1,Myh6,Tnni3 24.840569 61
## 105 4 Gja1,Myh6,Tnni3,Tnnt2 33.523855 54
## 106 3 Gja1,Myh6,Tnnt2 24.898218 57
## 107 2 Gja1,Tnni3 10.684950 85
## 108 3 Gja1,Tnni3,Tnnt2 19.368235 67
## 109 2 Gja1,Tnnt2 10.742598 88
## 110 2 Mef2c,Myh6 11.269029 71
## 111 3 Mef2c,Myh6,Tnni3 17.484240 41
## 112 4 Mef2c,Myh6,Tnni3,Tnnt2 23.740991 30
## 113 3 Mef2c,Myh6,Tnnt2 17.525779 43
## 114 2 Mef2c,Tnni3 7.284394 102
## 115 3 Mef2c,Tnni3,Tnnt2 13.541144 60
## 116 2 Mef2c,Tnnt2 7.325932 109
## 117 2 Myh6,Tnni3 95.421586 91
## 118 3 Myh6,Tnni3,Tnnt2 131.792399 72
## 119 2 Myh6,Tnnt2 96.302401 94
## 120 2 Tnni3,Tnnt2 72.500162 118
## Cell.Types
## 1 0
## 2 0
## 3 0
## 4 0
## 5 0
## 6 0
## 7 0
## 8 0
## 9 0
## 10 0
## 11 0
## 12 0
## 13 0
## 14 0
## 15 0
## 16 0
## 17 0
## 18 0
## 19 0
## 20 0
## 21 0
## 22 0
## 23 0
## 24 0
## 25 0
## 26 0
## 27 0
## 28 0
## 29 0
## 30 0
## 31 0
## 32 0
## 33 0
## 34 0
## 35 0
## 36 0
## 37 0
## 38 0
## 39 0
## 40 0
## 41 0
## 42 0
## 43 0
## 44 0
## 45 0
## 46 0
## 47 0
## 48 0
## 49 0
## 50 0
## 51 0
## 52 0
## 53 0
## 54 0
## 55 0
## 56 0
## 57 0
## 58 0
## 59 0
## 60 0
## 61 0
## 62 0
## 63 0
## 64 0
## 65 0
## 66 0
## 67 0
## 68 0
## 69 0
## 70 0
## 71 0
## 72 0
## 73 0
## 74 0
## 75 0
## 76 0
## 77 0
## 78 0
## 79 0
## 80 0
## 81 0
## 82 0
## 83 0
## 84 0
## 85 0
## 86 0
## 87 0
## 88 0
## 89 0
## 90 0
## 91 0
## 92 0
## 93 0
## 94 0
## 95 0
## 96 0
## 97 0
## 98 0
## 99 0
## 100 0
## 101 0
## 102 0
## 103 0
## 104 0
## 105 0
## 106 0
## 107 0
## 108 0
## 109 0
## 110 0
## 111 0
## 112 0
## 113 0
## 114 0
## 115 0
## 116 0
## 117 0
## 118 0
## 119 0
## 120 0为了允许从基因列表查询搜索富集的细胞类型,scfind使用查询优化程序。首先,函数markerGenes将统计在数据集中具有最高支持度的子查询。 每个基因集的TF-IDF得分允许用户识别最佳子查询以找到最相关的细胞类型。
best_subquery <- result[which.max(result$tfidf),] # get the best subquery by ranking TF-IDF score
best_subquery <- strsplit(as.character(best_subquery$Query), ",")[[1]] # obtain gene list
hyperQueryCellTypes(
scfind_index,
gene.list = best_subquery
)## cell_type cell_hits total_cells pval
## 1 Heart.cardiac muscle cell 57 83 0
## 2 Heart.endocardial cell 3 65 1
## 3 Heart.endothelial cell 7 178 1
## 4 Heart.fibroblast 5 222 1hyperQueryCellTypes函数返回与给定数据集中的所有细胞类型对应的p值列表。它还输出一组细胞,其基因与列表中基因共表达。
练习1
在Heart数据集中查找所有细胞类型的标记基因
heart_cell_types <- cellTypeNames(scfind_index, "Heart")
for(cell_type_name in heart_cell_types)
{
result <- cellTypeMarkers(
scfind_index,
cell.types = cell_type_name,
sort.field = "f1",
background = heart_cell_types)
print(result)
}## cellType genes tp fp fn precision recall
## 11309 Heart.cardiac muscle cell Xirp2 51 4 32 0.9272727 0.6144578
## 6628 Heart.cardiac muscle cell Myom2 53 8 30 0.8688524 0.6385542
## 8925 Heart.cardiac muscle cell Ryr2 51 8 32 0.8644068 0.6144578
## 5699 Heart.cardiac muscle cell Ldb3 53 13 30 0.8030303 0.6385542
## 10657 Heart.cardiac muscle cell Trdn 49 6 34 0.8909091 0.5903614
## f1
## 11309 0.7391304
## 6628 0.7361111
## 8925 0.7183099
## 5699 0.7114094
## 10657 0.7101449
## cellType genes tp fp fn precision recall f1
## 4581 Heart.endocardial cell Gpm6a 50 5 15 0.9090909 0.7692308 0.8333333
## 1736 Heart.endocardial cell Bmx 52 16 13 0.7647059 0.8000000 0.7819549
## 6851 Heart.endocardial cell Npr3 61 32 4 0.6559140 0.9384615 0.7721519
## 7533 Heart.endocardial cell Plagl1 51 18 14 0.7391304 0.7846154 0.7611941
## 2552 Heart.endocardial cell Comp 45 10 20 0.8181818 0.6923077 0.7500001
## cellType genes tp fp fn precision recall
## 1951 Heart.endothelial cell C1qtnf9 153 17 25 0.9000000 0.8595505
## 76 Heart.endothelial cell 1190002H23Rik 161 33 17 0.8298969 0.9044943
## 10534 Heart.endothelial cell Tcf15 157 30 21 0.8395722 0.8820225
## 2274 Heart.endothelial cell Cd300lg 163 50 15 0.7652582 0.9157303
## 4850 Heart.endothelial cell Gpihbp1 168 58 10 0.7433628 0.9438202
## f1
## 1951 0.8793103
## 76 0.8655914
## 10534 0.8602740
## 2274 0.8337595
## 4850 0.8316832
## cellType genes tp fp fn precision recall f1
## 2074 Heart.erythrocyte Cd68 51 5 4 0.9107143 0.9272727 0.9189188
## 2346 Heart.erythrocyte Clec4a2 50 4 5 0.9259259 0.9090909 0.9174312
## 5623 Heart.erythrocyte Lyz1 55 12 0 0.8208955 1.0000000 0.9016393
## 983 Heart.erythrocyte Alox5ap 55 13 0 0.8088235 1.0000000 0.8943089
## 3393 Heart.erythrocyte Emr1 48 5 7 0.9056604 0.8727272 0.8888889
## cellType genes tp fp fn precision recall
## 3024 Heart.fibroblast Col1a1 209 18 13 0.9207048 0.9414415
## 11653 Heart.fibroblast Tcf21 193 6 29 0.9698492 0.8693694
## 8609 Heart.fibroblast Pdgfra 194 8 28 0.9603961 0.8738739
## 3830 Heart.fibroblast Dpt 215 40 7 0.8431373 0.9684685
## 683 Heart.fibroblast 6330406I15Rik 190 11 32 0.9452736 0.8558559
## f1
## 3024 0.9309577
## 11653 0.9168646
## 8609 0.9150944
## 3830 0.9014676
## 683 0.8983452
## cellType genes tp fp fn precision recall
## 6968 Heart.smooth muscle cell Rgs4 20 9 1 0.6896551 0.9523810
## 5662 Heart.smooth muscle cell Nrip2 15 3 6 0.8333333 0.7142857
## 5779 Heart.smooth muscle cell Olfr558 16 6 5 0.7272727 0.7619048
## 890 Heart.smooth muscle cell Ano1 15 5 6 0.7500000 0.7142857
## 3565 Heart.smooth muscle cell Gm13889 18 11 3 0.6206896 0.8571429
## f1
## 6968 0.8000000
## 5662 0.7692308
## 5779 0.7441860
## 890 0.7317073
## 3565 0.7200000_练习2__
输入与“心肌收缩力”相关的基因列表,找到具有最高支持度的最佳基因组。识别此查询富集的细胞类型。
## Ignored Gh, Nos1, Grk2, Ins2, Dnah8, Ren2, Kcnmb2. Not found in the index## calculating tfidf for the reduced expression matrix...best_sub_query <- as.character(result[which.max(result$tfidf), c("Query")])
best_sub_query <- strsplit(best_sub_query, ",")[[1]]
hyperQueryCellTypes(scfind_index, best_sub_query)## cell_type cell_hits total_cells pval
## 1 Heart.cardiac muscle cell 57 83 0
## 2 Heart.endocardial cell 3 65 1
## 3 Heart.endothelial cell 7 178 1
## 4 Heart.fibroblast 4 222 18.9.6 In-silico gating
使用findCellTypes函数,可以执行in-silico gating以识别细胞类型子集,类似细胞排序。 在基因名称前面分别加上逻辑运算符,包括“-”,"*“,”no“和”intermediate"表达式。 在这里,我们使用运算符将Thymus数据集的T细胞分为效应T调节细胞和效应记忆T细胞子集。
effector_t_reg_cells <- c("*Ptprc", "-Il7r", "Ctla4", "-Il7r")
effector_memory_t_cells <- c("-Il2ra", "*Ptprc", "Il7r")
subset_treg <- findCellTypes(scfind_index, effector_t_reg_cells, "Thymus") ## Found 41 cells co-expressing Ctla4 ∧ Ptprc## Excluded 7 cells expressing Il7r## Found 167 cells co-expressing Il7r ∧ Ptprc## Excluded 13 cells expressing Il2ra## $`Thymus.T cell`
## [1] 28 54 80 121 125 144 161 165 166 180 229 235 251 320
## [15] 366 371 476 497 663 667 713 737 739 740 786 879 888 918
## [29] 928 953 1098 1225 1232 1277## $`Thymus.T cell`
## [1] 1 18 19 34 48 96 100 101 137 138 150 171 177 186
## [15] 198 215 237 254 267 284 292 293 312 313 323 329 362 376
## [29] 405 416 430 455 456 500 535 546 555 561 574 580 599 610
## [43] 634 673 681 686 687 698 701 712 718 719 722 733 735 745
## [57] 754 755 789 790 800 808 814 830 837 846 848 850 851 861
## [71] 893 895 896 897 902 907 908 913 916 920 921 930 931 946
## [85] 949 956 970 979 989 997 1020 1046 1047 1054 1055 1068 1076 1087
## [99] 1115 1124 1128 1129 1130 1140 1148 1152 1159 1168 1170 1190 1206 1213
## [113] 1226 1227 1237 1240 1251 1255 1275 1282 1284 1290 1298 1305 1307 1312
## [127] 1315
##
## $`Thymus.stromal cell`
## [1] 6 7 9 12 17 18 20 25 27 34 50 52 59 63 65 68 69
## [18] 71 72 79 80 84 88 98 100 104 106使用来自Thymus的SingleCellExperiment的TSNE图信息来展示gating结果。
map <- data.frame(
tm10x_thymus@reducedDims[['TSNE']],
cell_type = as.character(colData(tm10x_thymus)$cell_type1),
stringsAsFactors = F
)
map <- subset(map, cell_type == "T cell")
plot_ly(map, x = ~X1 , y = ~X2, type="scatter")## No scatter mode specifed:
## Setting the mode to markers
## Read more about this attribute -> https://plot.ly/r/reference/#scatter-modemap$cell_type[subset_treg$`Thymus.T cell`] <- "Effector T Regulatory Cell"
map$cell_type[subset_tmem$`Thymus.T cell`] <- "Effector Memory T Cell"
plot_ly(map, x = ~X1 , y = ~X2, type="scatter", color = ~cell_type)## No scatter mode specifed:
## Setting the mode to markers
## Read more about this attribute -> https://plot.ly/r/reference/#scatter-mode8.9.7 sessionInfo()
## R version 3.6.0 (2019-04-26)
## Platform: x86_64-w64-mingw32/x64 (64-bit)
## Running under: Windows 7 x64 (build 7601) Service Pack 1
##
## Matrix products: default
##
## locale:
## [1] LC_COLLATE=Chinese (Simplified)_People's Republic of China.936
## [2] LC_CTYPE=Chinese (Simplified)_People's Republic of China.936
## [3] LC_MONETARY=Chinese (Simplified)_People's Republic of China.936
## [4] LC_NUMERIC=C
## [5] LC_TIME=Chinese (Simplified)_People's Republic of China.936
##
## attached base packages:
## [1] splines parallel stats4 stats graphics grDevices utils
## [8] datasets methods base
##
## other attached packages:
## [1] plotly_4.9.0 scfind_3.2.0
## [3] scmap_1.7.0 googleVis_0.6.4
## [5] corrplot_0.84 ggbeeswarm_0.6.0
## [7] ggthemes_4.2.0 scater_1.13.9
## [9] ouija_0.99.0 Rcpp_1.0.1
## [11] SLICER_0.2.0 destiny_2.15.0
## [13] monocle_2.13.0 DDRTree_0.1.5
## [15] irlba_2.3.3 VGAM_1.1-1
## [17] ggplot2_3.2.0 Matrix_1.2-17
## [19] TSCAN_1.23.0 SingleCellExperiment_1.7.0
## [21] SummarizedExperiment_1.15.5 DelayedArray_0.11.4
## [23] BiocParallel_1.19.0 Biobase_2.45.0
## [25] GenomicRanges_1.37.14 GenomeInfoDb_1.21.1
## [27] IRanges_2.19.10 S4Vectors_0.23.17
## [29] BiocGenerics_0.31.5 RColorBrewer_1.1-2
## [31] M3Drop_1.11.4 numDeriv_2016.8-1.1
## [33] matrixStats_0.54.0 scRNA.seq.funcs_0.1.0
## [35] knitr_1.23
##
## loaded via a namespace (and not attached):
## [1] R.methodsS3_1.7.1 coda_0.19-3
## [3] tidyr_0.8.3 acepack_1.4.1
## [5] R.utils_2.9.0 data.table_1.12.2
## [7] rpart_4.1-15 inline_0.3.15
## [9] RCurl_1.95-4.12 callr_3.3.0
## [11] cowplot_1.0.0 RANN_2.6.1
## [13] combinat_0.0-8 proxy_0.4-23
## [15] spatstat.data_1.4-0 httpuv_1.5.1
## [17] StanHeaders_2.18.1-10 assertthat_0.2.1
## [19] viridis_0.5.1 lle_1.1
## [21] xfun_0.8 hms_0.5.0
## [23] evaluate_0.14 promises_1.0.1
## [25] DEoptimR_1.0-8 caTools_1.17.1.2
## [27] readxl_1.3.1 igraph_1.2.4.1
## [29] htmlwidgets_1.3 sparsesvd_0.1-4
## [31] tensorA_0.36.1 hash_2.2.6.1
## [33] purrr_0.3.2 crosstalk_1.0.0
## [35] dplyr_0.8.3 backports_1.1.4
## [37] bookdown_0.12 moments_0.14
## [39] deldir_0.1-22 vctrs_0.2.0
## [41] TTR_0.23-4 abind_1.4-5
## [43] RcppEigen_0.3.3.5.0 withr_2.1.2
## [45] robustbase_0.93-5 checkmate_1.9.4
## [47] vcd_1.4-4 xts_0.11-2
## [49] prettyunits_1.0.2 mclust_5.4.5
## [51] goftest_1.1-1 cluster_2.1.0
## [53] splancs_2.01-40 ape_5.3
## [55] lazyeval_0.2.2 laeken_0.5.0
## [57] crayon_1.3.4 elliptic_1.4-0
## [59] labeling_0.3 pkgconfig_2.0.2
## [61] slam_0.1-45 nlme_3.1-140
## [63] vipor_0.4.5 nnet_7.3-12
## [65] rlang_0.4.0 sgeostat_1.0-27
## [67] rsvd_1.0.1 randomForest_4.6-14
## [69] cellranger_1.1.0 polyclip_1.10-0
## [71] lmtest_0.9-37 loo_2.1.0
## [73] carData_3.0-2 boot_1.3-23
## [75] zoo_1.8-6 base64enc_0.1-3
## [77] beeswarm_0.2.3 processx_3.4.0
## [79] pheatmap_1.0.12 png_0.1-7
## [81] viridisLite_0.3.0 bitops_1.0-6
## [83] R.oo_1.22.0 KernSmooth_2.23-15
## [85] DelayedMatrixStats_1.7.1 stringr_1.4.0
## [87] tripack_1.3-8 scales_1.0.0
## [89] magrittr_1.5 plyr_1.8.4
## [91] gplots_3.0.1.1 gdata_2.18.0
## [93] zlibbioc_1.31.0 compiler_3.6.0
## [95] HSMMSingleCell_1.5.0 bbmle_1.0.20
## [97] cli_1.1.0 XVector_0.25.0
## [99] ps_1.3.0 htmlTable_1.13.1
## [101] Formula_1.2-3 MASS_7.3-51.4
## [103] mgcv_1.8-28 tidyselect_0.2.5
## [105] stringi_1.4.3 forcats_0.4.0
## [107] highr_0.8 densityClust_0.3
## [109] yaml_2.2.0 BiocSingular_1.1.5
## [111] latticeExtra_0.6-28 ggrepel_0.8.1
## [113] grid_3.6.0 orthopolynom_1.0-5
## [115] tools_3.6.0 rio_0.5.16
## [117] rstudioapi_0.10 foreign_0.8-71
## [119] snowfall_1.84-6.1 gridExtra_2.3
## [121] cubature_2.0.3 smoother_1.1
## [123] alphahull_2.2 scatterplot3d_0.3-41
## [125] Rtsne_0.15 digest_0.6.20
## [127] FNN_1.1.3 shiny_1.3.2
## [129] qlcMatrix_0.9.7 car_3.0-3
## [131] later_0.8.0 httr_1.4.0
## [133] contfrac_1.1-12 hypergeo_1.2-13
## [135] colorspace_1.4-1 tensor_1.5
## [137] ranger_0.11.2 reldist_1.6-6
## [139] MCMCglmm_2.29 statmod_1.4.32
## [141] spatstat.utils_1.13-0 sp_1.3-1
## [143] xtable_1.8-4 jsonlite_1.6
## [145] spatstat_1.60-1 corpcor_1.6.9
## [147] rstan_2.19.2 zeallot_0.1.0
## [149] R6_2.4.0 Hmisc_4.2-0
## [151] pillar_1.4.2 htmltools_0.3.6
## [153] mime_0.7 DT_0.7
## [155] glue_1.3.1 VIM_4.8.0
## [157] BiocNeighbors_1.3.2 deSolve_1.23
## [159] class_7.3-15 codetools_0.2-16
## [161] pkgbuild_1.0.3 lattice_0.20-38
## [163] tibble_2.1.3 curl_3.3
## [165] gtools_3.8.1 zip_2.0.3
## [167] openxlsx_4.1.0.1 survival_2.44-1.1
## [169] limma_3.41.6 rmarkdown_1.14
## [171] docopt_0.6.1 fastICA_1.2-2
## [173] munsell_0.5.0 e1071_1.7-2
## [175] GenomeInfoDbData_1.2.1 haven_2.1.1
## [177] reshape2_1.4.3 gtable_0.3.0## Warning: 程辑包'Seurat'是用R版本3.6.1 来建造的## Registered S3 method overwritten by 'R.oo':
## method from
## throw.default R.methodsS3## Warning: 程辑包'dplyr'是用R版本3.6.1 来建造的##
## 载入程辑包:'dplyr'## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union## Warning: 程辑包'cowplot'是用R版本3.6.1 来建造的##
## ********************************************************## Note: As of version 1.0.0, cowplot does not change the## default ggplot2 theme anymore. To recover the previous## behavior, execute:
## theme_set(theme_cowplot())## ********************************************************References
Altschul, Stephen F., Warren Gish, Webb Miller, Eugene W. Myers, and David J. Lipman. 1990. “Basic Local Alignment Search Tool.” Journal of Molecular Biology 215 (3): 403–10. https://doi.org/10.1016/s0022-2836(05)80360-2.
Cannoodt, Robrecht, Wouter Saelens, and Yvan Saeys. 2016. “Computational Methods for Trajectory Inference from Single-Cell Transcriptomics.” Eur. J. Immunol. 46 (11): 2496–2506. https://doi.org/10.1002/eji.201646347.
Consortium, Tabula Muris, and others. 2018. “Single-Cell Transcriptomics of 20 Mouse Organs Creates a Tabula Muris.” Nature 562 (7727): 367.
Deng, Q., D. Ramskold, B. Reinius, and R. Sandberg. 2014. “Single-Cell RNA-Seq Reveals Dynamic, Random Monoallelic Gene Expression in Mammalian Cells.” Science 343 (6167): 193–96. https://doi.org/10.1126/science.1245316.
Dijk, David van, Juozas Nainys, Roshan Sharma, Pooja Kathail, Ambrose J Carr, Kevin R Moon, Linas Mazutis, Guy Wolf, Smita Krishnaswamy, and Dana Pe’er. 2017. “MAGIC: A Diffusion-Based Imputation Method Reveals Gene-Gene Interactions in Single-Cell RNA-sequencing Data.” bioRxiv, February, 111591.
Guo, Minzhe, Hui Wang, S. Steven Potter, Jeffrey A. Whitsett, and Yan Xu. 2015. “SINCERA: A Pipeline for Single-Cell RNA-Seq Profiling Analysis.” PLoS Comput Biol 11 (11): e1004575. https://doi.org/10.1371/journal.pcbi.1004575.
Kiselev, Vladimir Yu, and Martin Hemberg. 2017. “Scmap - a Tool for Unsupervised Projection of Single Cell RNA-seq Data.” bioRxiv, July, 150292.
Kiselev, Vladimir Yu, Kristina Kirschner, Michael T Schaub, Tallulah Andrews, Andrew Yiu, Tamir Chandra, Kedar N Natarajan, et al. 2017. “SC3: Consensus Clustering of Single-Cell RNA-Seq Data.” Nat Meth 14 (5): 483–86. https://doi.org/10.1038/nmeth.4236.
Levine, Jacob H., Erin F. Simonds, Sean C. Bendall, Kara L. Davis, El-ad D. Amir, Michelle D. Tadmor, Oren Litvin, et al. 2015. “Data-Driven Phenotypic Dissection of AML Reveals Progenitor-Like Cells That Correlate with Prognosis.” Cell 162 (1): 184–97. https://doi.org/10.1016/j.cell.2015.05.047.
Li, Wei Vivian, and Jingyi Jessica Li. 2017. “scImpute: Accurate and Robust Imputation for Single Cell RNA-Seq Data.” bioRxiv, June, 141598.
Muraro, Mauro J., Gitanjali Dharmadhikari, Dominic Grün, Nathalie Groen, Tim Dielen, Erik Jansen, Leon van Gurp, et al. 2016. “A Single-Cell Transcriptome Atlas of the Human Pancreas.” Cell Systems 3 (4): 385–394.e3. https://doi.org/10.1016/j.cels.2016.09.002.
Regev, Aviv, Sarah Teichmann, Eric S Lander, Ido Amit, Christophe Benoist, Ewan Birney, Bernd Bodenmiller, et al. 2017. “The Human Cell Atlas.” bioRxiv, May, 121202.
Segerstolpe, Åsa, Athanasia Palasantza, Pernilla Eliasson, Eva-Marie Andersson, Anne-Christine Andréasson, Xiaoyan Sun, Simone Picelli, et al. 2016. “Single-Cell Transcriptome Profiling of Human Pancreatic Islets in Health and Type 2 Diabetes.” Cell Metabolism 24 (4): 593–607. https://doi.org/10.1016/j.cmet.2016.08.020.
Welch, Joshua D., Alexander J. Hartemink, and Jan F. Prins. 2016. “SLICER: Inferring Branched, Nonlinear Cellular Trajectories from Single Cell RNA-Seq Data.” Genome Biol 17 (1). https://doi.org/10.1186/s13059-016-0975-3.